Speech is the most natural form of communication in human beings. Most applications/websites currently communicate with their users using text. But what if applications interacted with us using voice, wouldn't that lead to a great user experience. This would require 3 major components: 1) Automatic speech recognition(ASR) - this would be required to convert spoken words from the end user into text which could be processed by machines, 2) Natural Language Processing (NLP)/ Natural Language Understanding (NLU)/ Question Answering (QA) system to to process the query and produce viable text response, and 3) Text to Speech (TTS) system to convert this text response into human speech to relay information to the end user.
Though various architectures and (pretrained) models are available online addressing each of the above components, most of them are for English language. What if you want to build this system in your language/ train such a system from scratch? I have already covered how you can train an ASR model from scratch using Kaldi/ HTK. In this blog, I will cover how to build text to speech system in Merlin, more importantly what are the important parts of the Merlin toolkit.
Currently there are amazing transformer based TTS systems which sound very natural (have very high Mean Opinion Score (MOS)). So you may ask, why Merlin which is a traditional toolkit? The answer to this is simple, though we have built awesome model, but still they are like a black box, we can't exactly pinpoint say what the internal layers are learning, what are some features which I can use in other similar tasks etc. The advantage with Merlin is that it is parametric model based approach with well defined and perceptually important speech features. You can say only use the feature extraction part of Merlin/ WORLD and then use a neural network on top of it for modelling. This will help you explicitly model important parts of spoken utterances like prosody and intonation, which can help you make your models more explainable and help you control how your model exploits these features to a small extent.
Though various architectures and (pretrained) models are available online addressing each of the above components, most of them are for English language. What if you want to build this system in your language/ train such a system from scratch? I have already covered how you can train an ASR model from scratch using Kaldi/ HTK. In this blog, I will cover how to build text to speech system in Merlin, more importantly what are the important parts of the Merlin toolkit.
Currently there are amazing transformer based TTS systems which sound very natural (have very high Mean Opinion Score (MOS)). So you may ask, why Merlin which is a traditional toolkit? The answer to this is simple, though we have built awesome model, but still they are like a black box, we can't exactly pinpoint say what the internal layers are learning, what are some features which I can use in other similar tasks etc. The advantage with Merlin is that it is parametric model based approach with well defined and perceptually important speech features. You can say only use the feature extraction part of Merlin/ WORLD and then use a neural network on top of it for modelling. This will help you explicitly model important parts of spoken utterances like prosody and intonation, which can help you make your models more explainable and help you control how your model exploits these features to a small extent.
A brief introduction
Developed by The Centre for Speech Technology Research, University of Edinburgh, United Kingdom
Paper : https://pdfs.semanticscholar.org/8339/47531a8cd6b79d17003adab58abb00edc0f2.pdf
GitHub: https://github.com/CSTR-Edinburgh/merlin
A good starting point: http://jrmeyer.github.io/tts/2017/02/14/Installing-Merlin.html
Front end: Festival and Ossian ; Vocoder: WORLD, WORLD2 and STRAIGHT
Provides neural network based regressors to learn the mapping from features (linguistic specification) to spectral representations. Components available: DNN, LSTM, biLSTM, GRUs
Like HTS, Merlin is not a complete TTS system. It provides the core acoustic modelling functions: linguistic feature vectorisation, acoustic and linguistic feature normalisation, neural network acoustic model training, and generation.
Paper : https://pdfs.semanticscholar.org/8339/47531a8cd6b79d17003adab58abb00edc0f2.pdf
GitHub: https://github.com/CSTR-Edinburgh/merlin
A good starting point: http://jrmeyer.github.io/tts/2017/02/14/Installing-Merlin.html
Front end: Festival and Ossian ; Vocoder: WORLD, WORLD2 and STRAIGHT
Provides neural network based regressors to learn the mapping from features (linguistic specification) to spectral representations. Components available: DNN, LSTM, biLSTM, GRUs
Like HTS, Merlin is not a complete TTS system. It provides the core acoustic modelling functions: linguistic feature vectorisation, acoustic and linguistic feature normalisation, neural network acoustic model training, and generation.
Installation
Open terminal and navigate to the directory where you would like to install merlin. Now clone the recent version of Merlin from it’s GitHub repository;
$ git clone https://github.com/CSTR-Edinburgh/merlin.git
This will create a directory named merlin with the necessary files. Ensure that you have a running Python 3.6+ environment
Next do -
$ cd merlin/tools
$ ./compile_tools.sh -> installs and sets up the required tools
$ pip install numpy scipy matplotlib lxml theano bandmat -> installs dependencies
$ ./compile_other_speech_tools.sh -> compiles the other speech tools like festvox
$ ./compile_htk.sh <username> <password> -> you can get this from registering on HTK website
$ cd htk/ -> go to htk directory
$ make hlmtools install-hlmtools
$ make hdecode install-hdecode
$ git clone https://github.com/CSTR-Edinburgh/merlin.git
This will create a directory named merlin with the necessary files. Ensure that you have a running Python 3.6+ environment
Next do -
$ cd merlin/tools
$ ./compile_tools.sh -> installs and sets up the required tools
$ pip install numpy scipy matplotlib lxml theano bandmat -> installs dependencies
$ ./compile_other_speech_tools.sh -> compiles the other speech tools like festvox
$ ./compile_htk.sh <username> <password> -> you can get this from registering on HTK website
$ cd htk/ -> go to htk directory
$ make hlmtools install-hlmtools
$ make hdecode install-hdecode
Error handling in installation
On MacOS:
You need to install X11. For this follow the steps as listed on http://unixnme.blogspot.com/2018/01/build-htk-on-macos.html
Next , the appropriate flags so that the system knows the location of X11:
$ export CPPFLAGS=-I/opt/X11/include
$ ln -s /opt/X11/include/X11 /usr/local/include/X11
For linux:
You would face an error saying there should be a tab instead of 8 spaces at line 77 of HLMTools. For this, go to HLMTools inside htk folder, then go and make changes in makefile —> at line 77 keep cursor at i of if and backspace till beginning of line. Next hit a tab and save.
You need to install X11. For this follow the steps as listed on http://unixnme.blogspot.com/2018/01/build-htk-on-macos.html
Next , the appropriate flags so that the system knows the location of X11:
$ export CPPFLAGS=-I/opt/X11/include
$ ln -s /opt/X11/include/X11 /usr/local/include/X11
For linux:
You would face an error saying there should be a tab instead of 8 spaces at line 77 of HLMTools. For this, go to HLMTools inside htk folder, then go and make changes in makefile —> at line 77 keep cursor at i of if and backspace till beginning of line. Next hit a tab and save.
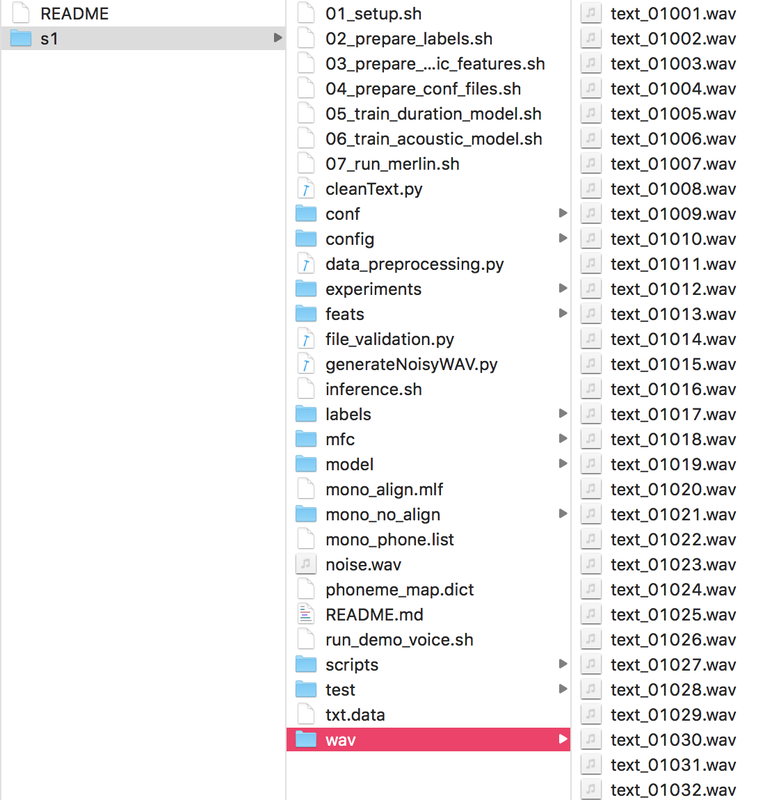
Data preparation (single speaker)
To prepare data for merlin need to follow few steps -
( text_01002 "kintu aadhunika paaqdxitya, na sirphaQ eka braahmanxa raamaanaqda ke, eka julaahe kabiira kaa guru hone se, balki donoq ke samakaaliina hone se bhii, inakaara karataa hei." ) ...
Where text_01001, text_01002 … are the name of audio and the row will have the corresponding text of the audio file.
3. If the audio files are clean (studio recorded files or recorded in very clean environment) then you need to add white noise of snr 50. This is because clean files cause error during force alignment as the GMM size reduces and it is not recognize the small clean part, hence it stops processing.
4. It's recommended to have fixed sample rate for all audio files (e.g 16Khz, 16 bit pcm, mono)
5. There should not be any leading and trailing spaces and extra space in text file.
6. For any Indian language there should be the question file corresponding to the language in merlin/misc/questions/ which contains details about the language.
7. Edit the setup.sh file (eg: merlin/egs/build_your_voice/s1/) according to the data, model and vocoder (as per your requirement)
8. Transliterate the unicode text to ILSL format.
- Wave file should be in one folder named wav, where the system will do the needful processing
- The text data should be as follow -
( text_01002 "kintu aadhunika paaqdxitya, na sirphaQ eka braahmanxa raamaanaqda ke, eka julaahe kabiira kaa guru hone se, balki donoq ke samakaaliina hone se bhii, inakaara karataa hei." ) ...
Where text_01001, text_01002 … are the name of audio and the row will have the corresponding text of the audio file.
3. If the audio files are clean (studio recorded files or recorded in very clean environment) then you need to add white noise of snr 50. This is because clean files cause error during force alignment as the GMM size reduces and it is not recognize the small clean part, hence it stops processing.
4. It's recommended to have fixed sample rate for all audio files (e.g 16Khz, 16 bit pcm, mono)
5. There should not be any leading and trailing spaces and extra space in text file.
6. For any Indian language there should be the question file corresponding to the language in merlin/misc/questions/ which contains details about the language.
7. Edit the setup.sh file (eg: merlin/egs/build_your_voice/s1/) according to the data, model and vocoder (as per your requirement)
8. Transliterate the unicode text to ILSL format.
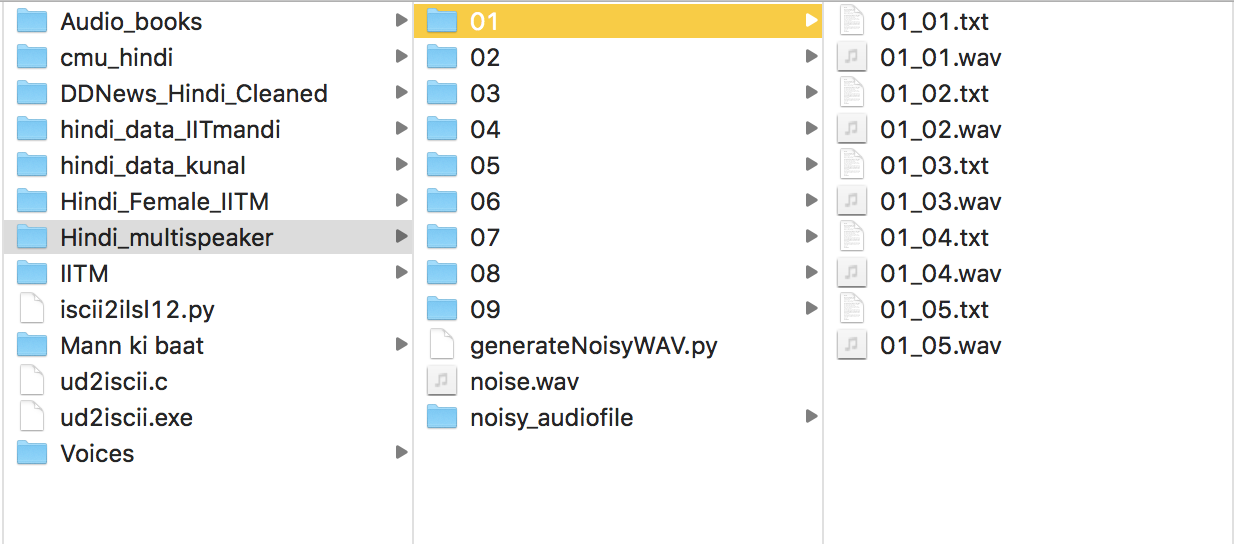
Data preparation (multiple speakers)
- Prepare text in transliterate form - isa buletxina ke mukhya samaacara …
- For each speaker prepare the txt and corresponding wav file as shown below -
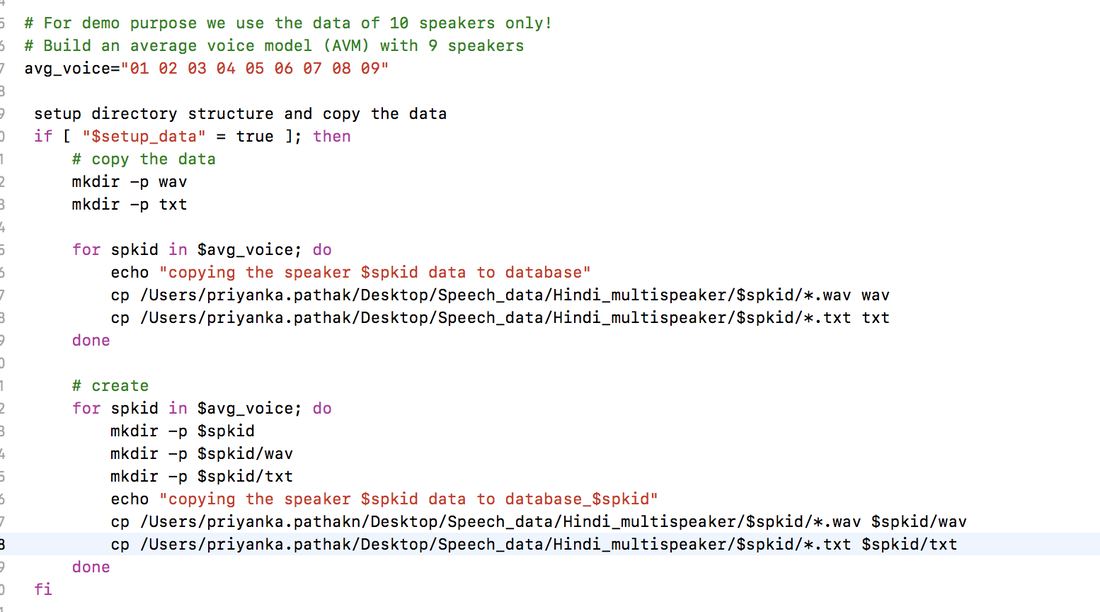
3. Modify setup.sh according to the data setup-
4. To enable multi-speaker change the script merlin/misc/scripts/alignment/state_align/forced_alignment.py at line 402.
5. For the remaining, follow the same steps as done in single speaker setup
5. For the remaining, follow the same steps as done in single speaker setup
Setup files and database
The very first step towards setting up the system is to make modifications in the scripts run_demo_voice.sh and setup.sh. Showcasing below the changes for script merlin/egs/hindi/s1/run_demo_voice.sh -
1. Experiment name (voice_name="hindi_voices")
1. Experiment name (voice_name="hindi_voices")
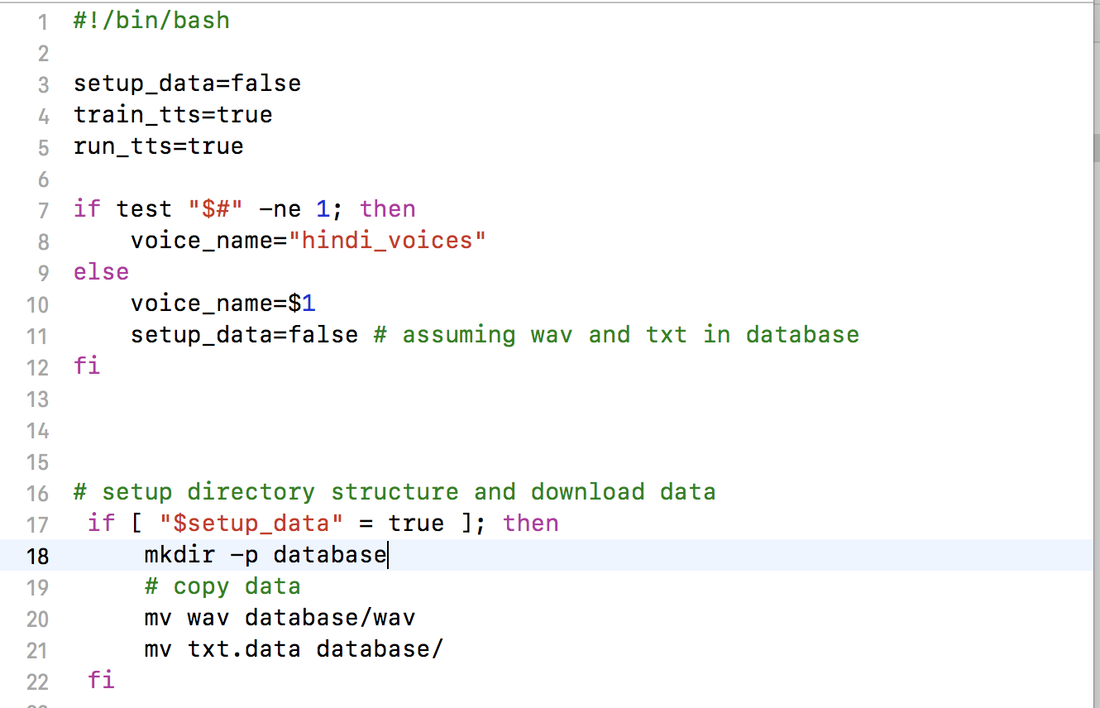
2. Setting up directory structure for experiment (merlin/egs/hindi/s1/setup.sh)
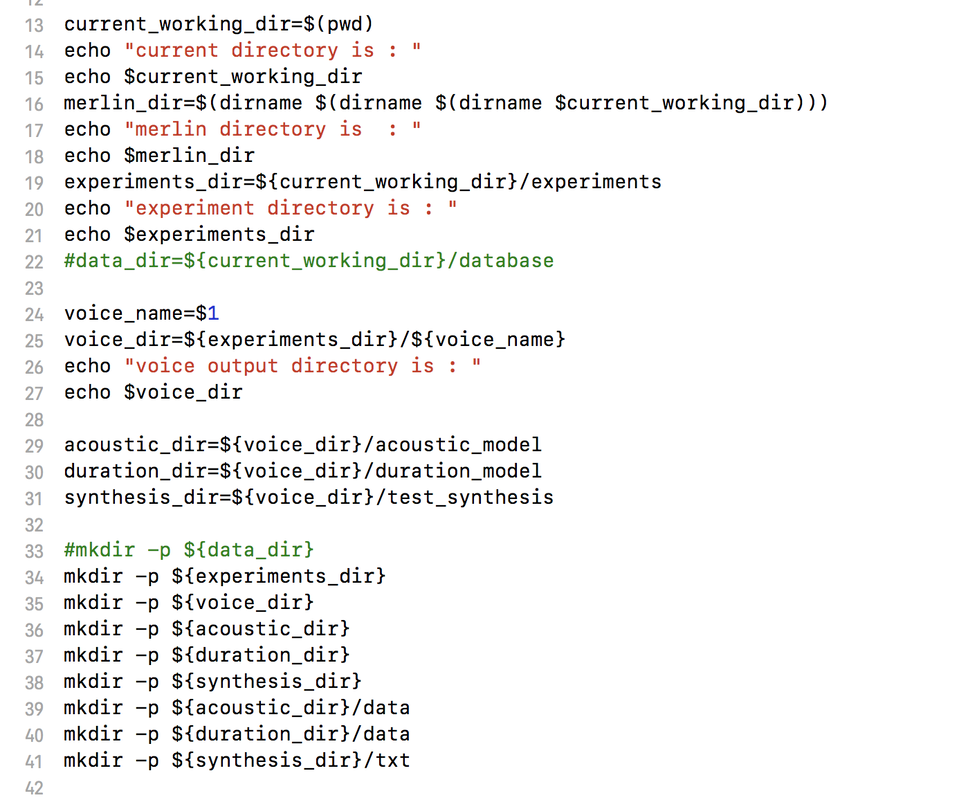
3. Generating the global_config_setting. In this step we do the following-
a) set up the paths
b) set the sampling frequency
c) specify the Vocoder (either WORLD, WORLD2, or STRAIGHT or MEGPHASE)
d) provide the question file based on language
a) set up the paths
b) set the sampling frequency
c) specify the Vocoder (either WORLD, WORLD2, or STRAIGHT or MEGPHASE)
d) provide the question file based on language
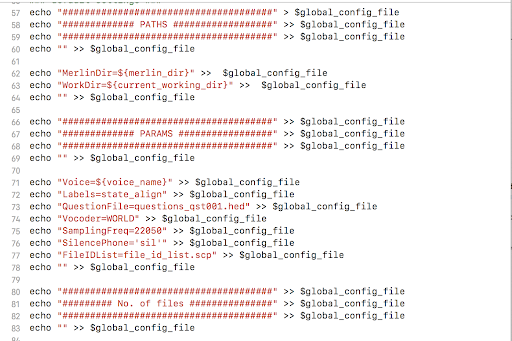
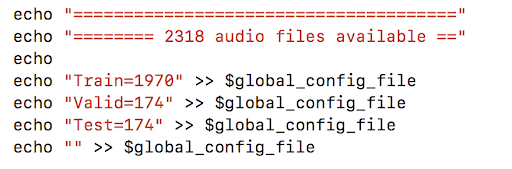
4. Specify the corpus details-
5. Set the tools to be used
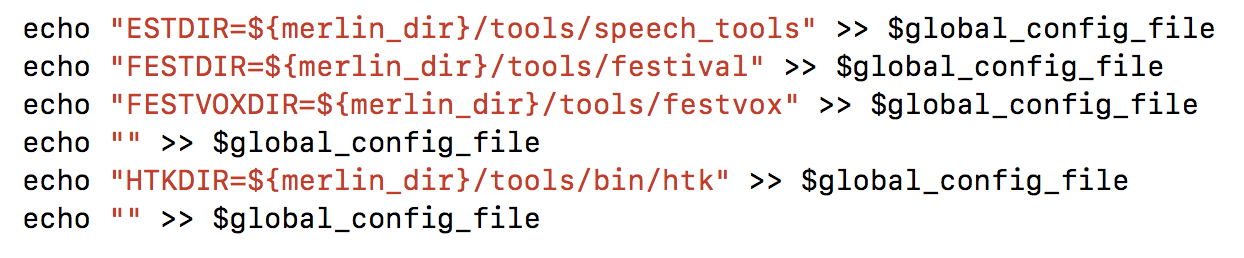
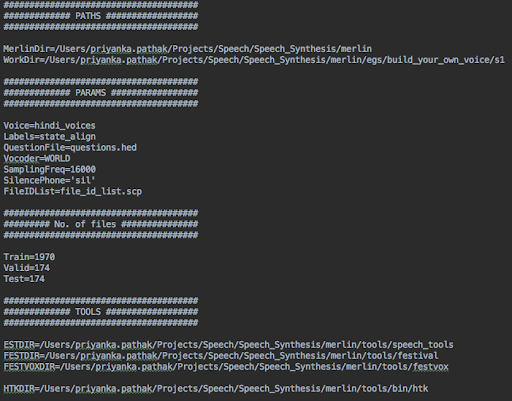
Here is a glimpse at the final global config file generated via the above process-
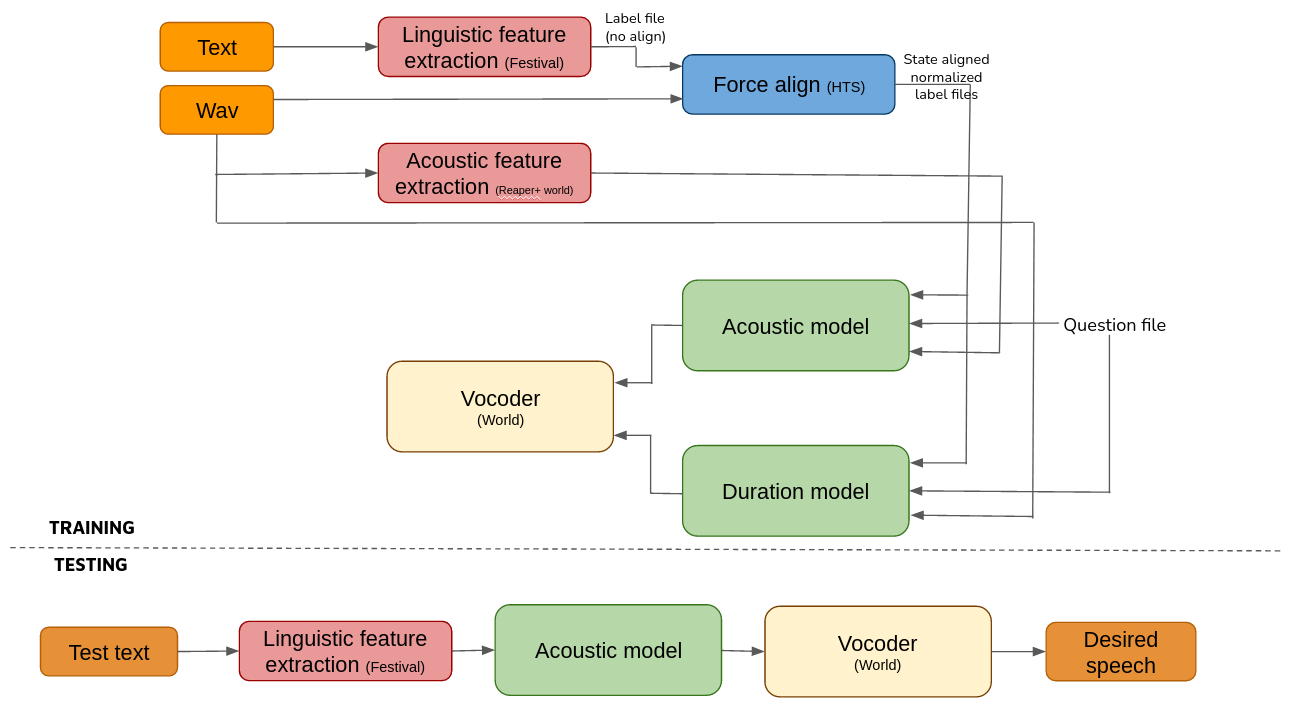
Let's have a sneak peak at the overall process before delving into the individual components
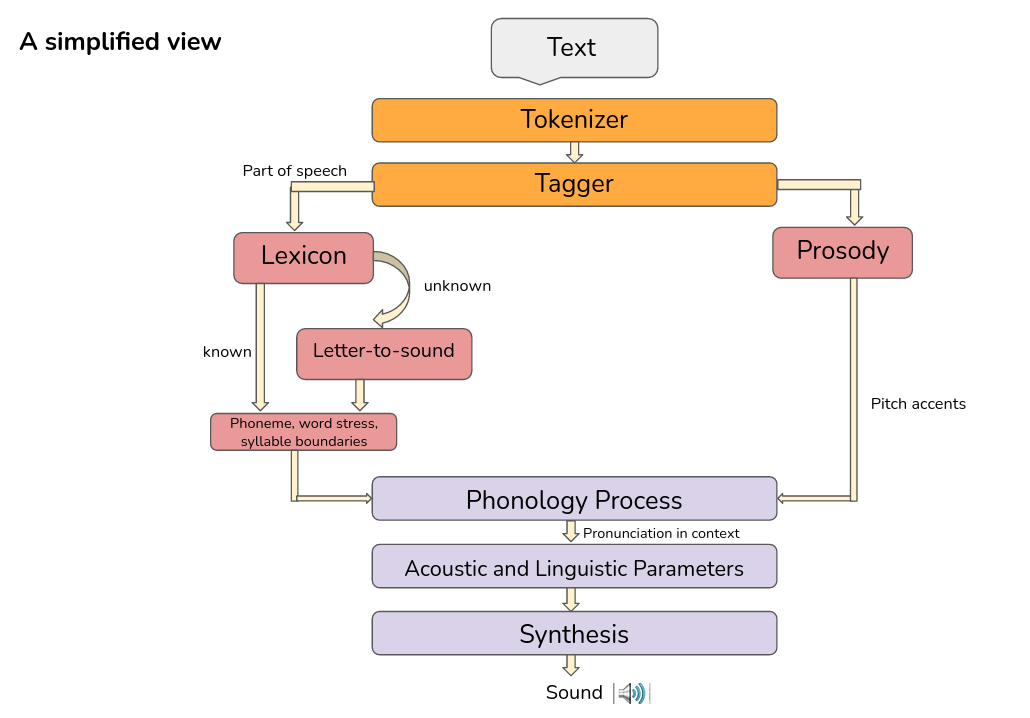

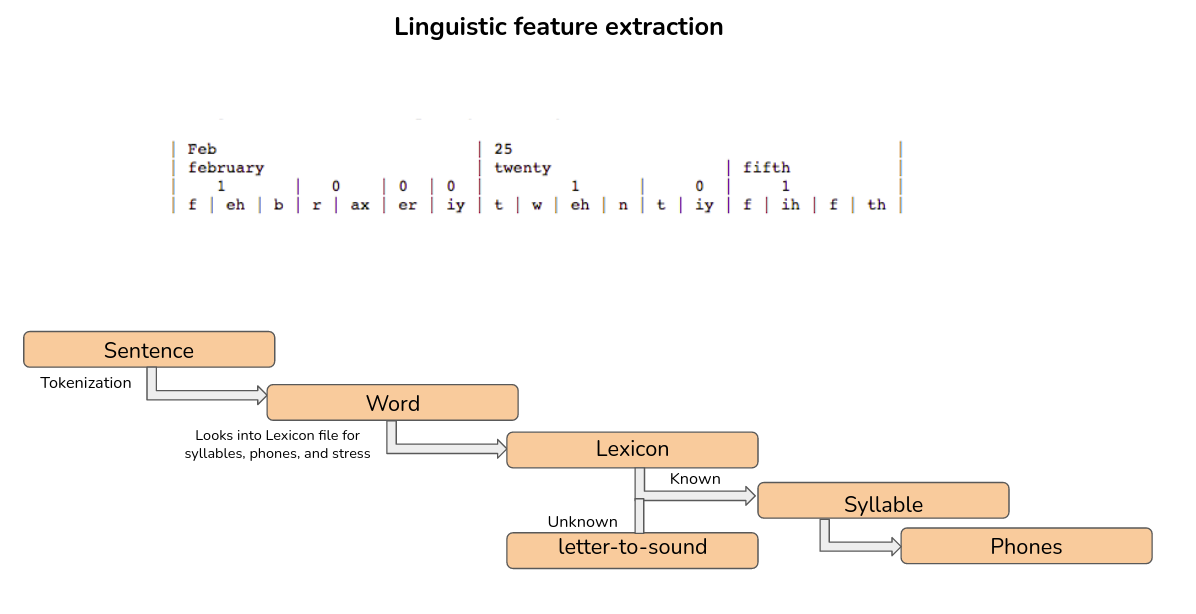
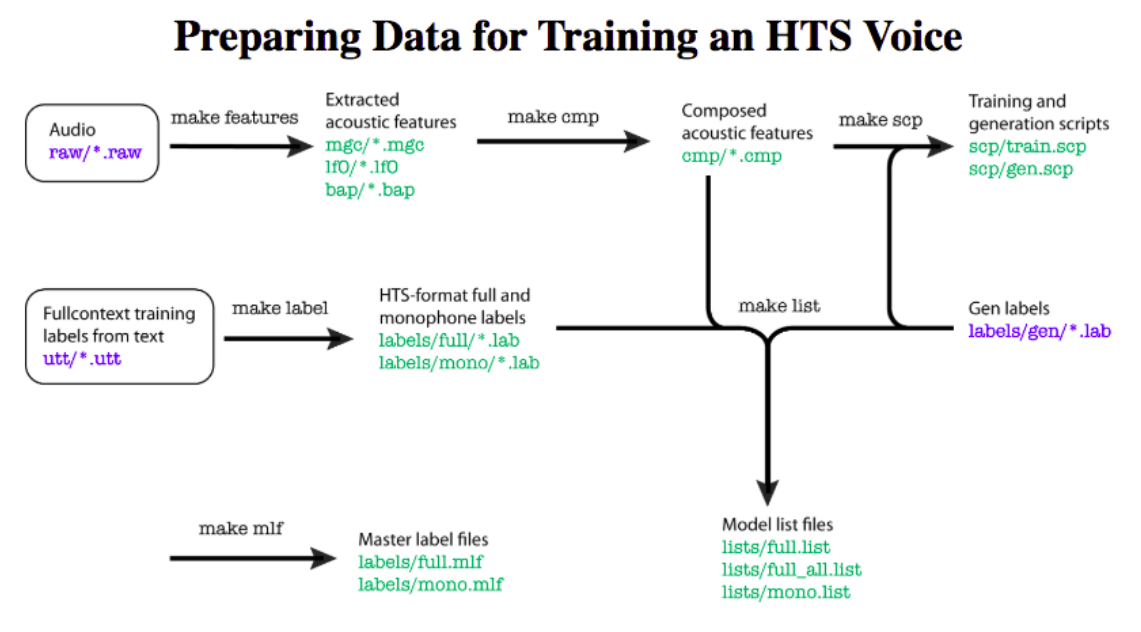
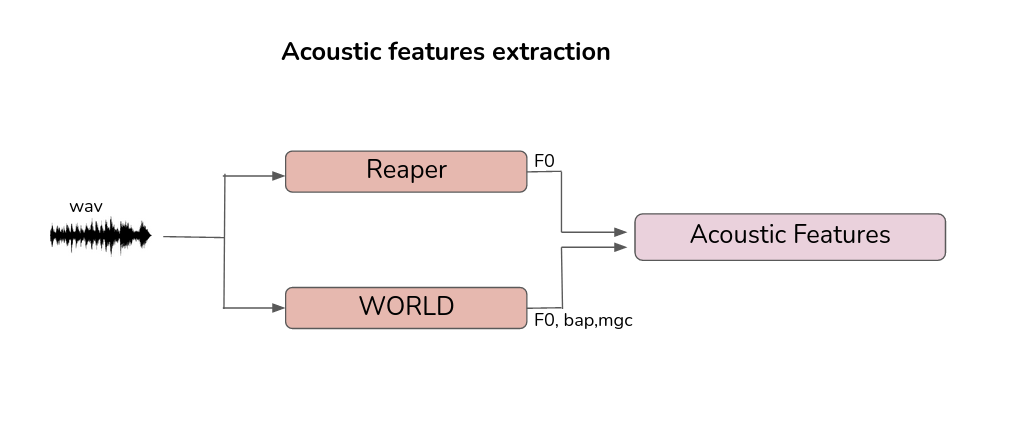
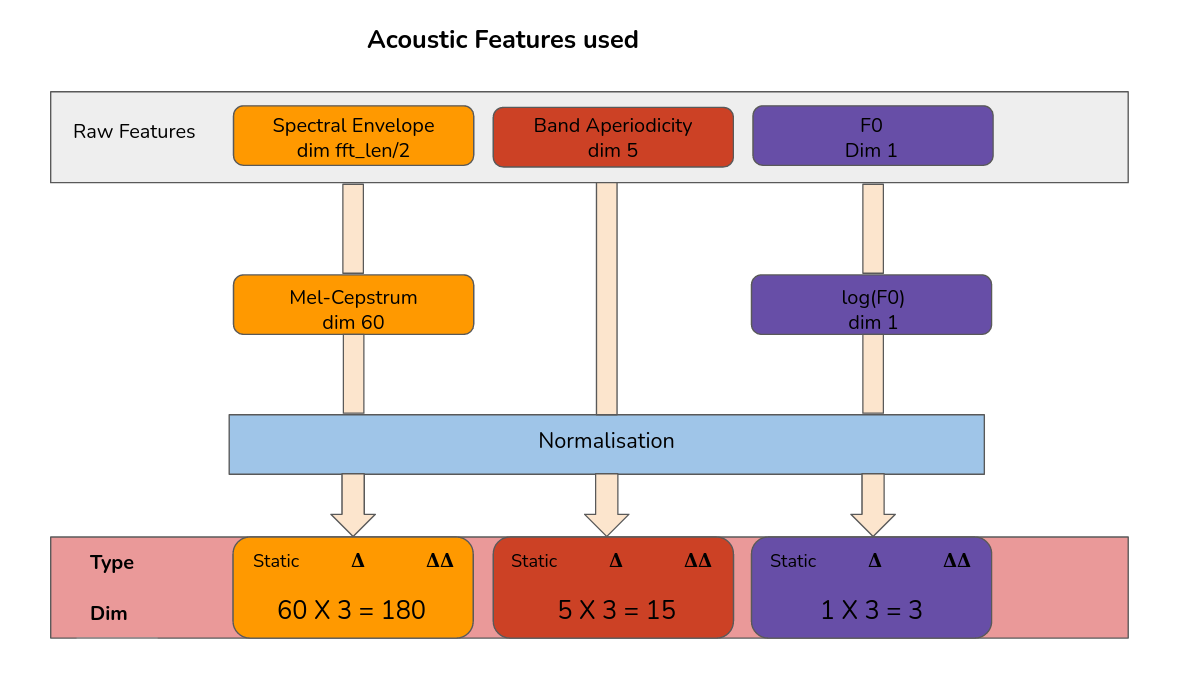
Let’s now look at the linguistic feature extraction process

Linguistic/ Prosodic processing -
As seen earlier, we note that we first generate scm files from my text data (which only contains commands written in scheme language, the text corresponding to the utterance and where to save the utt file). The festival binary takes this as input, extracts some intermediate linguistic features and writes them in the utt file. Finally, dumpfeats (present in speech tool directory) takes these as input and calculates the final linguistic features that are stored in lab files.
As seen earlier, we note that we first generate scm files from my text data (which only contains commands written in scheme language, the text corresponding to the utterance and where to save the utt file). The festival binary takes this as input, extracts some intermediate linguistic features and writes them in the utt file. Finally, dumpfeats (present in speech tool directory) takes these as input and calculates the final linguistic features that are stored in lab files.

Let us list the various features that festival calculates and thus are present in the utt file
Original utterance: prasidda kabiira adhyetaa, purusxottama agravaala kaa yaha shodha aalekha, usa raamaanaqda kii khoja karataa hei.
Original utterance: prasidda kabiira adhyetaa, purusxottama agravaala kaa yaha shodha aalekha, usa raamaanaqda kii khoja karataa hei.
- Word segmentation from sentence (name adhyetaa ; punc , ; whitespace " " ; prepunctuation "" ; )
- POS tags (name raamaanaqda ; pos_index 8 ; pos_index_score 0 ; pos nnp ; phr_pos n ; phrase_score -5.15147 ; pbreak_index 1 ; pbreak_index_score 0 ; pbreak NB ;)
- Syllable and stress information (name syl ; stress 1 ;)
- Phoneme level duration information (name p ; dur_factor 0.143214 ; end 0.321526 ; us_diphone_left p_ ; source_end 0.233423 ; )
- Phone level f0 and POS information (f0 87.0538 ; pos 7.25662 ; )
- Diphone information (name d-ax ; sig "[Val wave]" ; coefs "[Val track]" ; middle_frame 3 ; end 0.888961 ; num_frames 10 ; )
- Relations: token, word, phrase, syllable, segment, sylstructure, intevent, intonation.
Digging a little more deeper-
A lexicon consists of 3 important parts (all optional in festival):
A lexicon consists of 3 important parts (all optional in festival):
- Compiled lexicon
A large list of words, their part of speech, syllabic structure, lexical stress and pronunciation - Addenda
A typically smaller list of entries which are specific to a task or implementation (eg SMS, ASR ..) - Letter to sound rules
A general letter to sound rule system is included in Festival allowing mapping of letters to phones by context-sensitive rules. It is of course not acceptable for a speech synthesizer to fail to pronounce something so a fall back position that can guarantee pronunciation is important. Letter to sound rules can help with this. Often words can be pronounced reasonably from letter to sound rules.
Lets see how each entry in the utt file is calculated:
- Word segmentation from sentence: This is simply done using by segmenting along ‘SPACE’, also noting down any punctuation that may come after a word.
- POS tags: In festival, they have a standard statistical part of speech tagger -> location of tagger is /Users/kunal.dhawan/merlin/tools/festival/lib
- Syllable and stress information: This is provided by us for all the words in the lexicon
- Phoneme level duration information: Including the explanation from festival website -

5. Phone level f0 information: Though festival itself calculates this information, this is not used finally in training the Merlin acoustic/ duration model. Still, detailed information regarding f0 extraction can be found at http://festvox.org/festtut/notes/festtut_6.html#SEC50

Phonesets
For a new language, we will have to define the phoneset from scratch. Hence, lets look into the phoneset defination.
The lexicons, letter to sound rules, waveform synthesizers, etc. all require the definition of a phoneset before they will operate.
A phoneset is a set of symbols which may be further defined in terms of features, such as vowel/consonant, place of articulation for consonants, type of vowel etc. The set of features and their values must be defined with the phoneset. The definition is used to ensure compatibility between sub-systems as well as allowing groups of phones in various prediction systems (e.g. duration)
For a new language, we will have to define the phoneset from scratch. Hence, lets look into the phoneset defination.
The lexicons, letter to sound rules, waveform synthesizers, etc. all require the definition of a phoneset before they will operate.
A phoneset is a set of symbols which may be further defined in terms of features, such as vowel/consonant, place of articulation for consonants, type of vowel etc. The set of features and their values must be defined with the phoneset. The definition is used to ensure compatibility between sub-systems as well as allowing groups of phones in various prediction systems (e.g. duration)

An example can be found here - https://github.com/google/language-resources/blob/master/bn/festvox/phonology.json

Labels
The full context label format represents phonemes in context. The different context elements are extracted by a frontend tool Festival. The label file basically has one phoneme-in-context per line.
1. Use Festival to Create Utts
Festival is the frontend tool we use to extract phonemes and contextual features from text. For training data, we have both text and audio, and Festival does the alignment with the audio to get the start and end times for each phone. Festival produces utt-format files containing a structured representation of the utterance and its properties.
2. Use HTS to Convert from Utt to Lab
HTS and Merlin use the same label file format. Use HTS to convert from the structured .utt format to the flattened .lab format.
The full context label format represents phonemes in context. The different context elements are extracted by a frontend tool Festival. The label file basically has one phoneme-in-context per line.
1. Use Festival to Create Utts
Festival is the frontend tool we use to extract phonemes and contextual features from text. For training data, we have both text and audio, and Festival does the alignment with the audio to get the start and end times for each phone. Festival produces utt-format files containing a structured representation of the utterance and its properties.
2. Use HTS to Convert from Utt to Lab
HTS and Merlin use the same label file format. Use HTS to convert from the structured .utt format to the flattened .lab format.

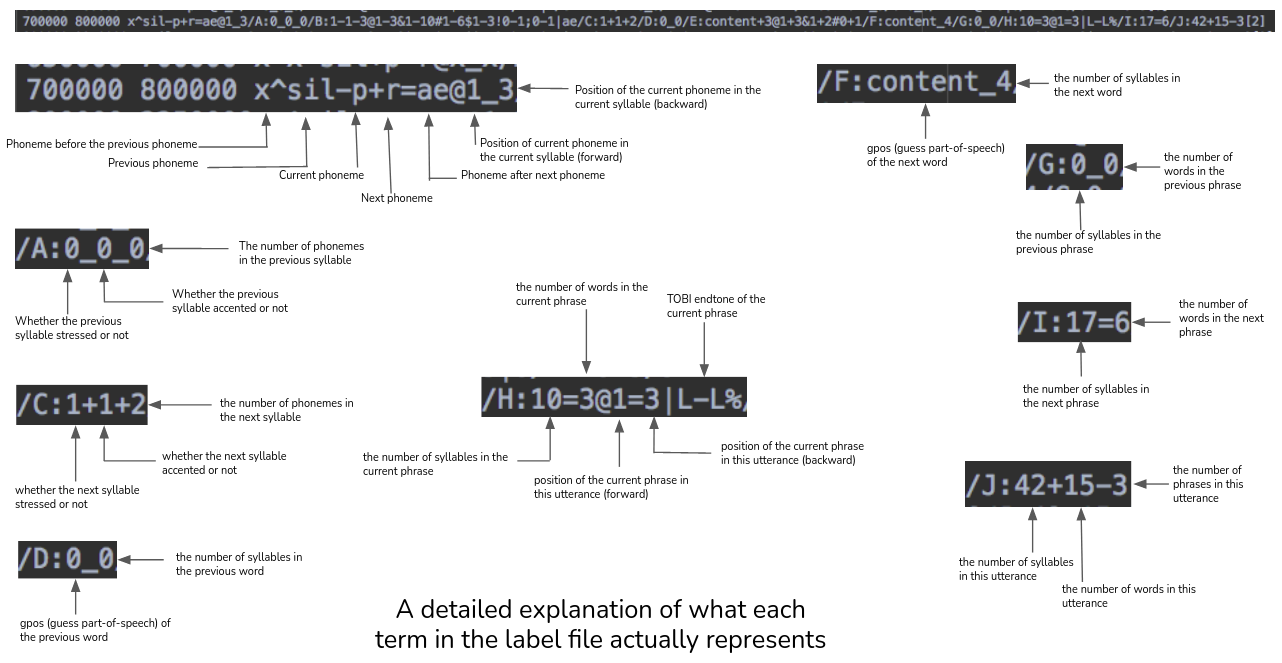
Presented below is a detailed explanation of what each term in the label file actually represents-
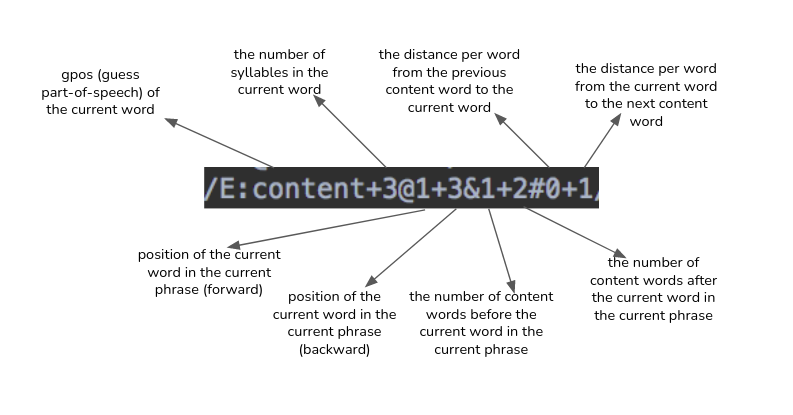
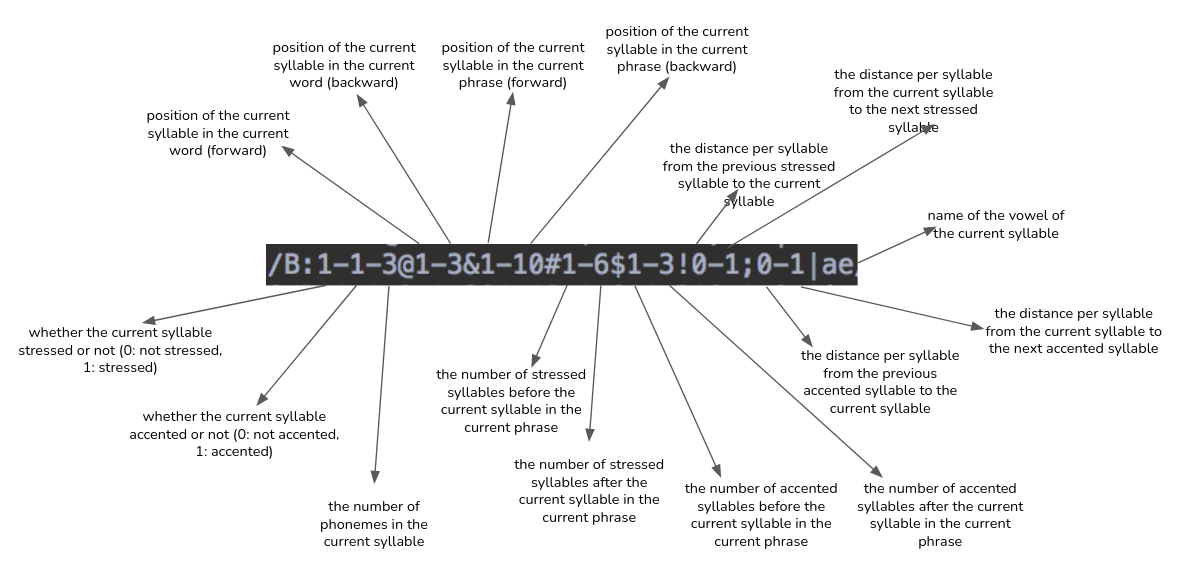
Preparing labels
Expects wav and text file directories as input and stores the corresponding labels in label directory
Input: 1) wav dir (ie database/wav)
2) txt dir (ie database/txt)
3) global config file (for configuration parameters)
Output: label dir (ie database/label)
Now, we can generate the labels either state aligned or phone aligned.
Let’s look at these one by one:
Input: 1) wav dir (ie database/wav)
2) txt dir (ie database/txt)
3) global config file (for configuration parameters)
Output: label dir (ie database/label)
Now, we can generate the labels either state aligned or phone aligned.
Let’s look at these one by one:
State aligned labels -
Step 1 : Prepare full-contextual labels (without timestamps) using Festival frontend
${WorkDir}/scripts/prepare_labels_from_txt.sh <text_input> <label_directory>.....
…..<global_config_file> <train=True>
The last input is true when we want to train the system, it is set to false when we are in the inference stage.
Inside this script, we first create the scheme file. This done using the python code genScmFile.py which is present at {MerlinDir}/misc/scripts/frontend/utils/genScmFile.py
The parameters it takes in are : python genScmFile.py <in_txt_dir/in_txt_file> <out_utt_dir> <out_scm_file> <out_file_id_list>
For us, <in_txt_dir/in_txt_file> = database/txt
<out_utt_dir> = database/label/prompt-utt
<out_scm_file> = database/label/train_sentences.scm
<out_file_id_list> = database/label/file_id_list.scp
Inside this script, if the input text files are given as a directory, it loops over all .txt files present and creates a python dictionary utt_text of all the texts
text = readtext(textfile)
utt_text[filename] = text
Else, if the input texts are given as a single text file, it reads it line by line, extracts the filename and text, remove the extra quotes from the text and creates the same dictionary.
Next, it orders the elements of the dictionary as per the filename using the command:
$ sorted_utt_text = collections.OrderedDict(sorted(utt_text.items()))
(reference - https://stackoverflow.com/questions/9001509/how-can-i-sort-a-dictionary-by-key )
Now, we simply write the scm and ID files:
Step 1 : Prepare full-contextual labels (without timestamps) using Festival frontend
${WorkDir}/scripts/prepare_labels_from_txt.sh <text_input> <label_directory>.....
…..<global_config_file> <train=True>
The last input is true when we want to train the system, it is set to false when we are in the inference stage.
Inside this script, we first create the scheme file. This done using the python code genScmFile.py which is present at {MerlinDir}/misc/scripts/frontend/utils/genScmFile.py
The parameters it takes in are : python genScmFile.py <in_txt_dir/in_txt_file> <out_utt_dir> <out_scm_file> <out_file_id_list>
For us, <in_txt_dir/in_txt_file> = database/txt
<out_utt_dir> = database/label/prompt-utt
<out_scm_file> = database/label/train_sentences.scm
<out_file_id_list> = database/label/file_id_list.scp
Inside this script, if the input text files are given as a directory, it loops over all .txt files present and creates a python dictionary utt_text of all the texts
text = readtext(textfile)
utt_text[filename] = text
Else, if the input texts are given as a single text file, it reads it line by line, extracts the filename and text, remove the extra quotes from the text and creates the same dictionary.
Next, it orders the elements of the dictionary as per the filename using the command:
$ sorted_utt_text = collections.OrderedDict(sorted(utt_text.items()))
(reference - https://stackoverflow.com/questions/9001509/how-can-i-sort-a-dictionary-by-key )
Now, we simply write the scm and ID files:
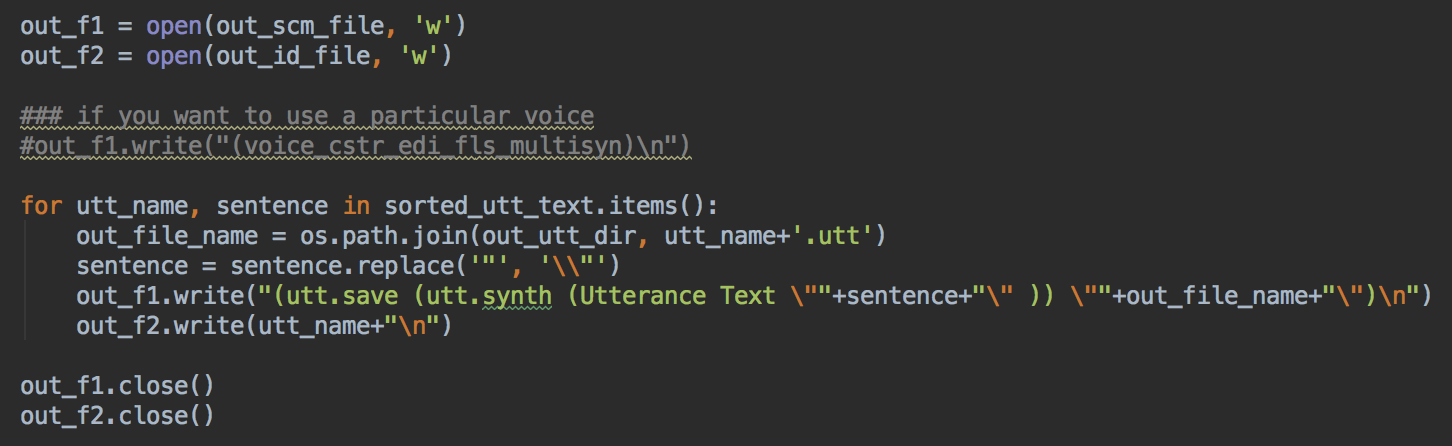

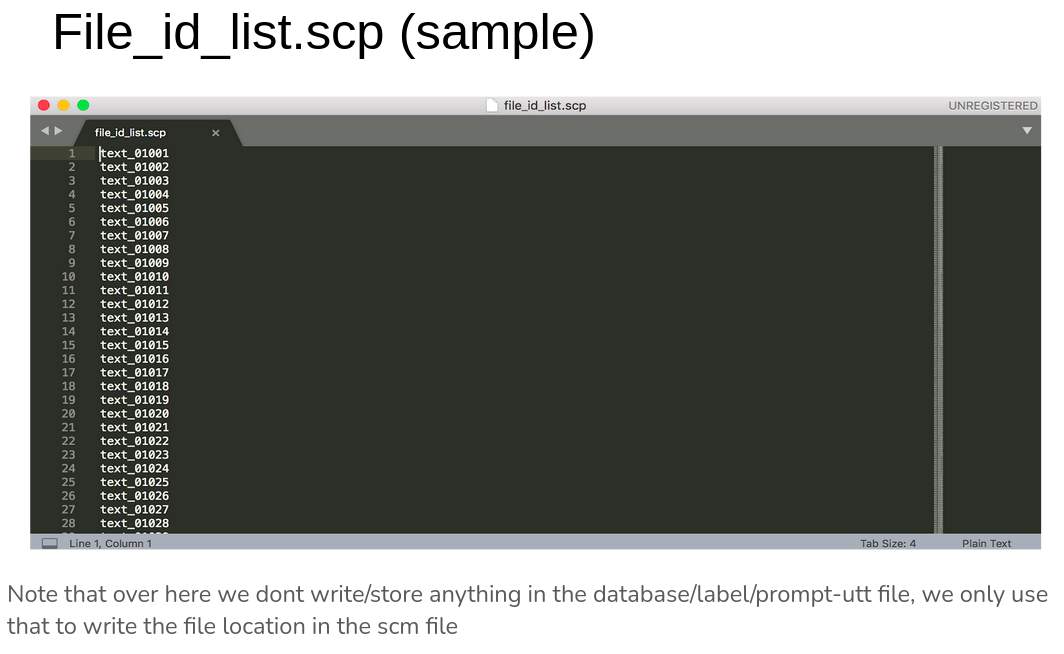
Next, we generate utts from scheme file using festival
Command : ${MERLIN}/tools/festival/bin/festival -b ${out_dir}/$scheme_file
This executable takes in only the text information from the scheme file and fills in the database/label/prompt-utt directory.n
A sample file from the directory looks like:
https://docs.google.com/document/d/1IMZjmnoQpWoAv8_eNgcYCLoJGfXeaD2HM5j4qe4rYYk/edit?usp=sharing
We can see that this contains various textual plus audio based features. This is done for each utterance in the database
Command : ${MERLIN}/tools/festival/bin/festival -b ${out_dir}/$scheme_file
This executable takes in only the text information from the scheme file and fills in the database/label/prompt-utt directory.n
A sample file from the directory looks like:
https://docs.google.com/document/d/1IMZjmnoQpWoAv8_eNgcYCLoJGfXeaD2HM5j4qe4rYYk/edit?usp=sharing
We can see that this contains various textual plus audio based features. This is done for each utterance in the database
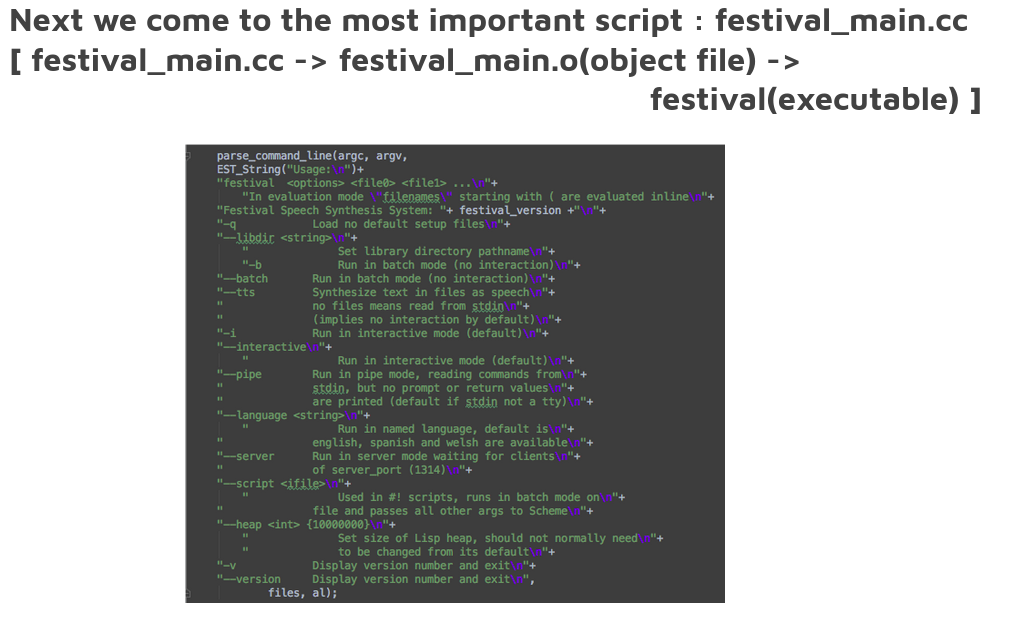
We note here that festival by default assumes the language to be English. Though it is important to note that Festival is also available for Indic languages, which can be seen at it’s site: http://festvox.org/
We noticed that though Festival accepted devnagri script text as input, but merlin didn’t do so, which was the reason we had to move on to the transliterate form.
But as by default we didn’t pass any language information to Festival, it assumed the data to be in English and thus extracted the features assuming English.
We need to modify this part of the code to extract features like POS and syllable level structure for Hindi specifically!
How to make festival running for Indian languages-
We noticed that though Festival accepted devnagri script text as input, but merlin didn’t do so, which was the reason we had to move on to the transliterate form.
But as by default we didn’t pass any language information to Festival, it assumed the data to be in English and thus extracted the features assuming English.
We need to modify this part of the code to extract features like POS and syllable level structure for Hindi specifically!
How to make festival running for Indian languages-
- Lexicon file (for each word in my text corpus, what is the phone level breakup)
- Phone file (list of unique phones in my language) Alignable text (https://github.com/google/language-resources/blob/master/bn/alignables.txt)
- Lexicon.scm file (rules for lexicon creation https://github.com/google/language-resources/blob/master/bn/festvox/lexicon.scm)
- POS tagger
- Phonology.json (https://github.com/google/language-resources/blob/master/bn/festvox/phonology.json)
- Festival prompts
Final aim -> get utt files, uske bad HTS sambhal lega :)
Next we convert these extracted utt files to label files -
${frontend}/festival_utt_to_lab/make_labels \
${out_dir}/prompt-lab \
${out_dir}/prompt-utt \
${FESTDIR}/examples/dumpfeats \
${frontend}/festival_utt_to_lab
Aim : Extract monophone and full-context labels from utterance files
labels=$1 -- Put the newly made labels here
utts=$2 -- Look for existing utterances here
dumpfeats=$3 -- This needs to point to Festival's dumpfeats script, usually in examples, e.g. /group/project/cstr2/s0676515/festival_my_install/festival/examples/dumpfeats
scripts=$4 -- Following scripts must be here: extra_feats.scm label.feats label-full.awk label-mono.awk
${frontend}/festival_utt_to_lab/make_labels \
${out_dir}/prompt-lab \
${out_dir}/prompt-utt \
${FESTDIR}/examples/dumpfeats \
${frontend}/festival_utt_to_lab
Aim : Extract monophone and full-context labels from utterance files
labels=$1 -- Put the newly made labels here
utts=$2 -- Look for existing utterances here
dumpfeats=$3 -- This needs to point to Festival's dumpfeats script, usually in examples, e.g. /group/project/cstr2/s0676515/festival_my_install/festival/examples/dumpfeats
scripts=$4 -- Following scripts must be here: extra_feats.scm label.feats label-full.awk label-mono.awk
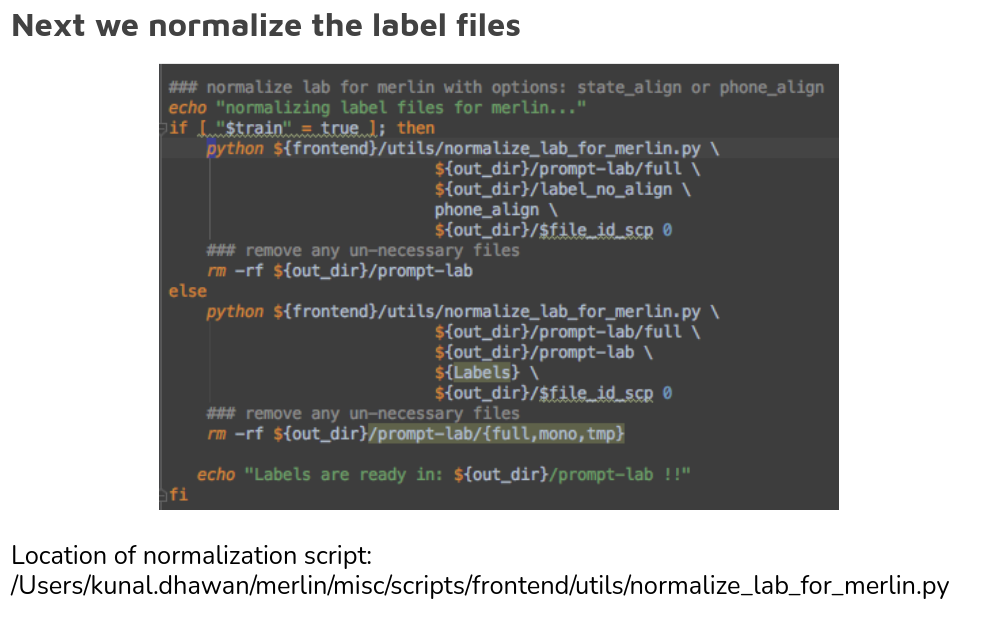


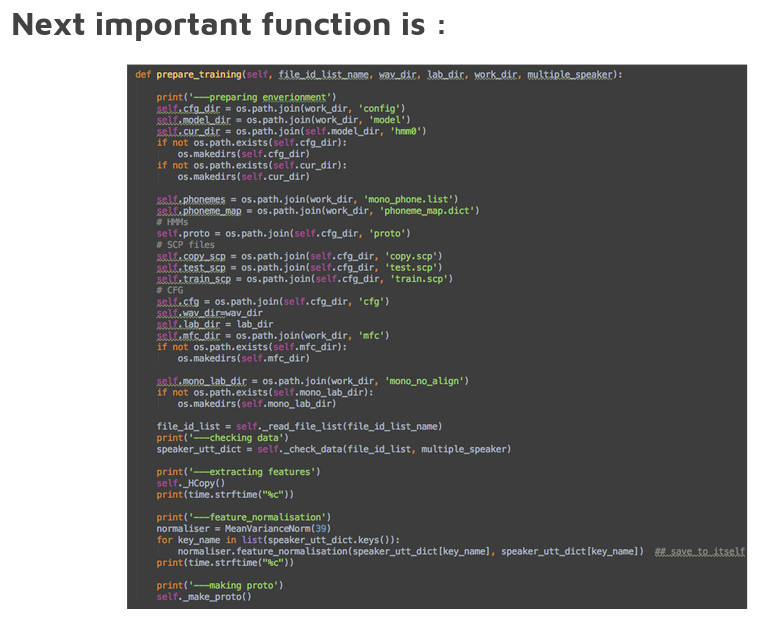

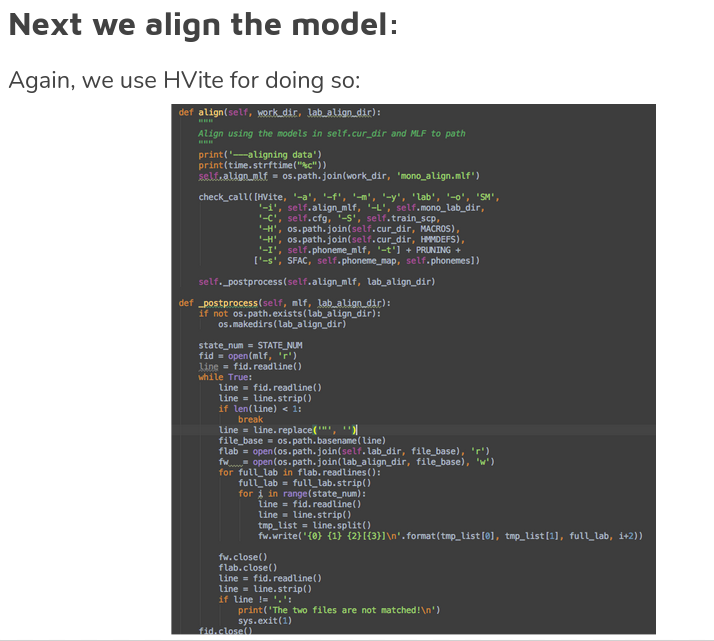
Personal touches-
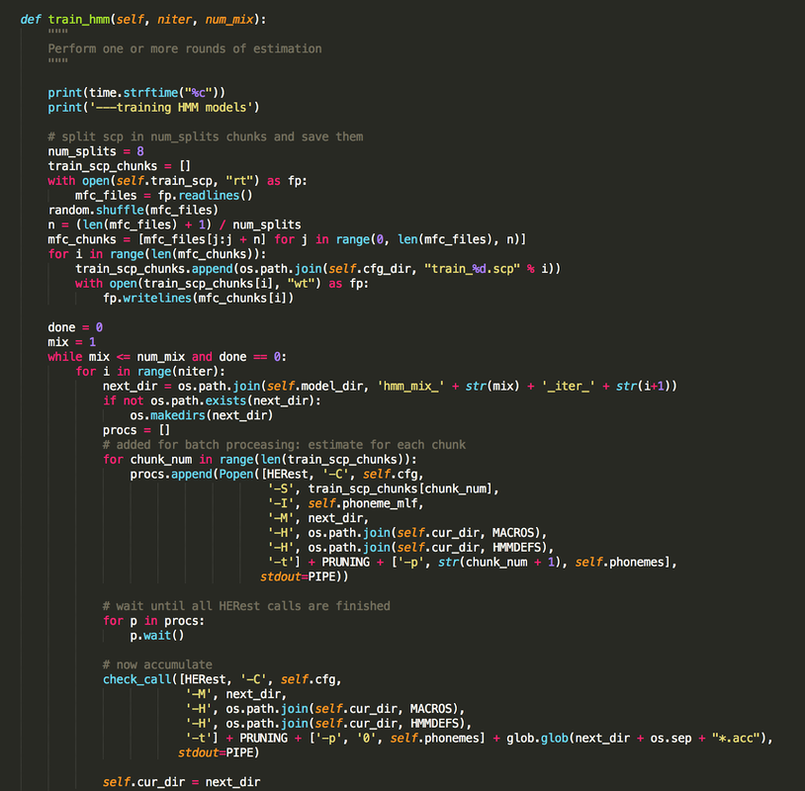
We called hmm fitting function with the parameters: train_hmm(7,32)
We had training data with ~11K utterances. When used directly, HRest( HMM training) gave an error of too much data. This error was resolved using solution from https://github.com/CSTR-Edinburgh/merlin/issues/293.
The main changes were:
We called hmm fitting function with the parameters: train_hmm(7,32)
We had training data with ~11K utterances. When used directly, HRest( HMM training) gave an error of too much data. This error was resolved using solution from https://github.com/CSTR-Edinburgh/merlin/issues/293.
The main changes were:
Neural networks take vectors as input, so the alphabet representation of linguistic features needs to be vectorized.
- HTS style: Check the HTS demo for the HTS style labels (http://hts.sp.nitech.ac.jp/).
- Provide HTS full-context labels with state-level alignments.
- Provide a question file that matches the HTS labels.
- The questions in the question file will be used to convert the full-context labels into binary and/or numerical features for vectorization. It is suggested to do a manual selection of the questions, as the number of questions will affect the dimensionality of the vectorized input features.
- Different from the HTS format question, the NN system also supports to extract numerical values using ‘CQS‘, e.g., ** CQS “Pos_C-Word_in_C-Phrase(Fw)” {:(d+)+}**, where ‘:‘ and ‘+‘ are separators, and ‘(d+)‘ is a regular expression to match a numerical feature.
- Provide HTS full-context labels with state-level alignments.
- Direct *vectorized* input: If prefer to do vectorization, can feed the system binary files directly. Prepare binary files with the following instructions:
- Align the input feature vectors with the acoustic features. Input and output features should have the same number of frames.
- Store the data in binary format with ‘float32‘ precision.
- In the config file, use an empty question file, and set appended_input_dim to be the dimensionality of the input vector.
- Align the input feature vectors with the acoustic features. Input and output features should have the same number of frames.
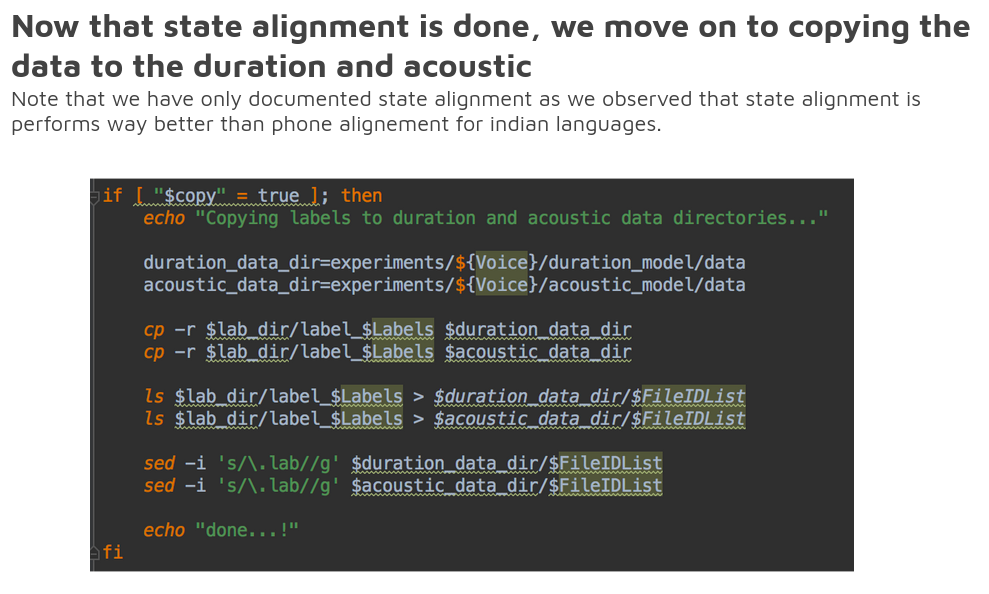
Preparing acoustic features
To build a NN system, we need to prepare linguistic features as system input and acoustic features as system output.
The default setting is assuming use of WORLD vocoder. The output includes -
To extract the acoustic features require wav files (input audio directory), feats (Output features directory), sampling frequency and the Vocoder name using in the current system. The current merlin system supports 16000, 22050, 41000, and 48000 Hz sampling frequency. So, as mentioned in earlier step please consider downsampling to 16000 Hz or upsampling to 48000 Hz.
The default setting is assuming use of WORLD vocoder. The output includes -
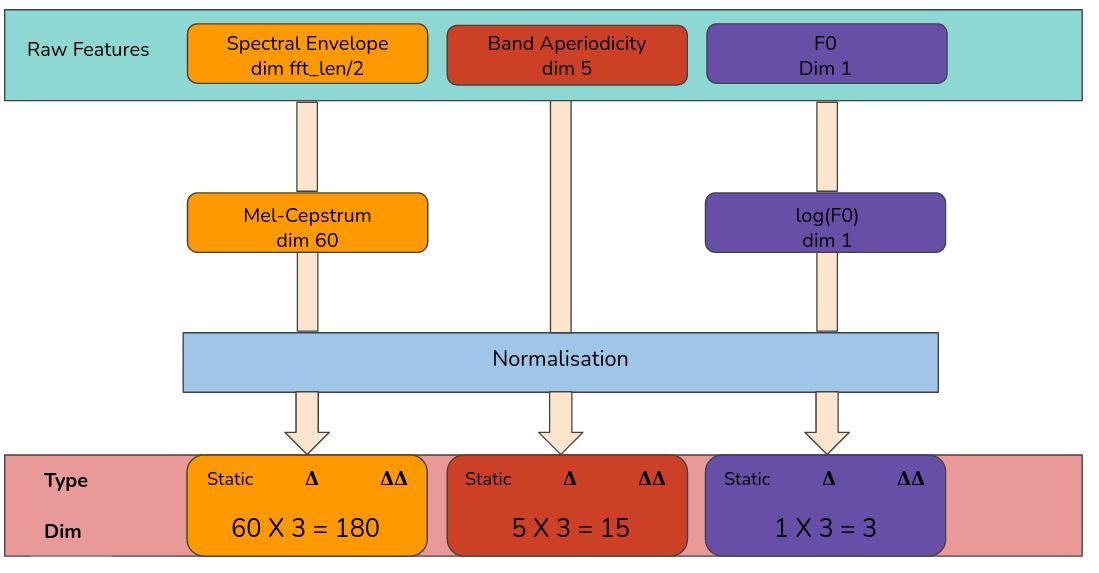
- mel-cepstral coefficients (MCC),
- band aperiodicities (BAP),
- Fundamental frequency (F0) in logarithmic scale.
- STRAIGHT -
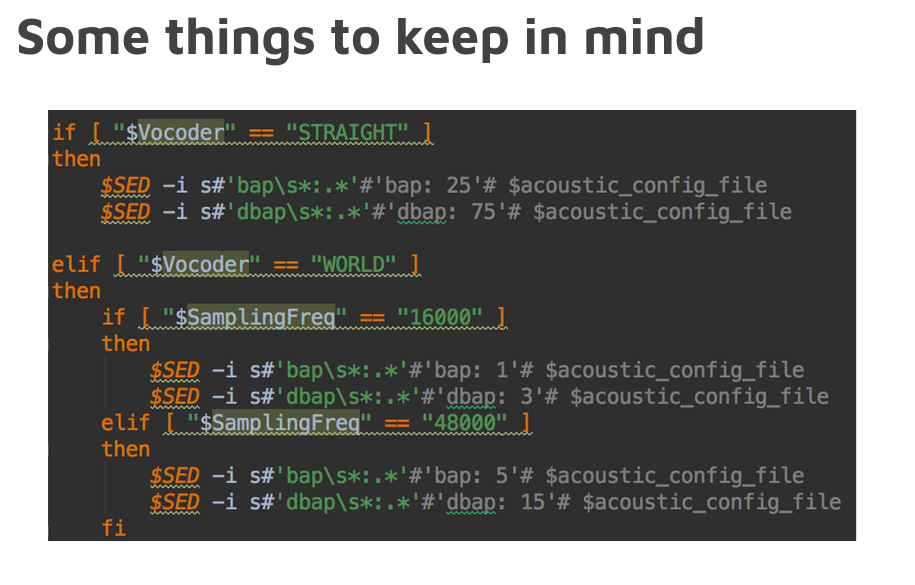
- [Outputs] mgc : 60
- [Outputs] bap : 25
- [Outputs] LF0 : 1
- WORLD -
- [Outputs] mgc : 60
- [Outputs] bap : variable dimension - BAP dim (1 for 16Khz, 5 for 48Khz)
- [Outputs] LF0 : 1
- WORLD2 -
- [Output] mgc : 60
- [Output] bap : 5
- [Output] LF0 : 1
- [Extensions] mgc_ext : .mgc
- [Extensions] bap_ext : .bap
- [Extensions] lf0_ext : .lf0
To extract the acoustic features require wav files (input audio directory), feats (Output features directory), sampling frequency and the Vocoder name using in the current system. The current merlin system supports 16000, 22050, 41000, and 48000 Hz sampling frequency. So, as mentioned in earlier step please consider downsampling to 16000 Hz or upsampling to 48000 Hz.
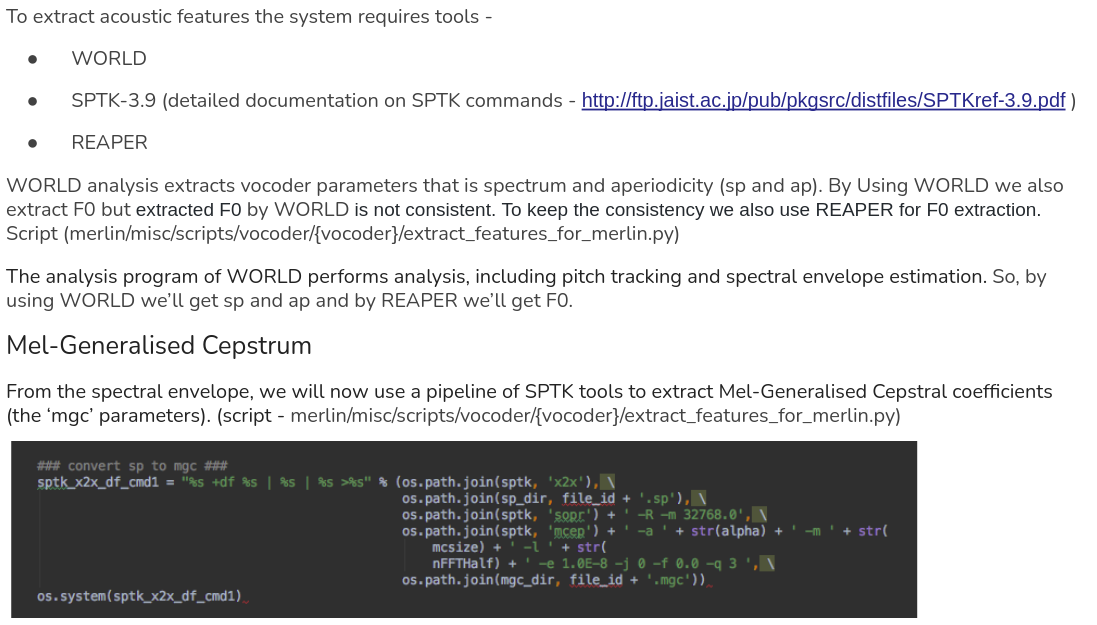
WORLD
WORLD - a high-quality speech analysis, manipulation and synthesis system
It can estimate Fundamental frequency (F0), aperiodicity and spectral envelope
and also generate the speech like input speech with only estimated parameters.
(1) F0 estimation by Dio() (same we estimate via Reaper)
(1-1) F0 is refined by StoneMask() if you need more accurate result.
(2) Spectral envelope estimation by CheapTrick()
(3) Aperiodicity estimation by D4C().
(4) You can manipulation these parameters in this phase.
(5) Voice synthesis by Synthesis()
To Know about Reaper please check the link - https://github.com/google/REAPER
WORLD - a high-quality speech analysis, manipulation and synthesis system
It can estimate Fundamental frequency (F0), aperiodicity and spectral envelope
and also generate the speech like input speech with only estimated parameters.
(1) F0 estimation by Dio() (same we estimate via Reaper)
(1-1) F0 is refined by StoneMask() if you need more accurate result.
(2) Spectral envelope estimation by CheapTrick()
(3) Aperiodicity estimation by D4C().
(4) You can manipulation these parameters in this phase.
(5) Voice synthesis by Synthesis()
To Know about Reaper please check the link - https://github.com/google/REAPER

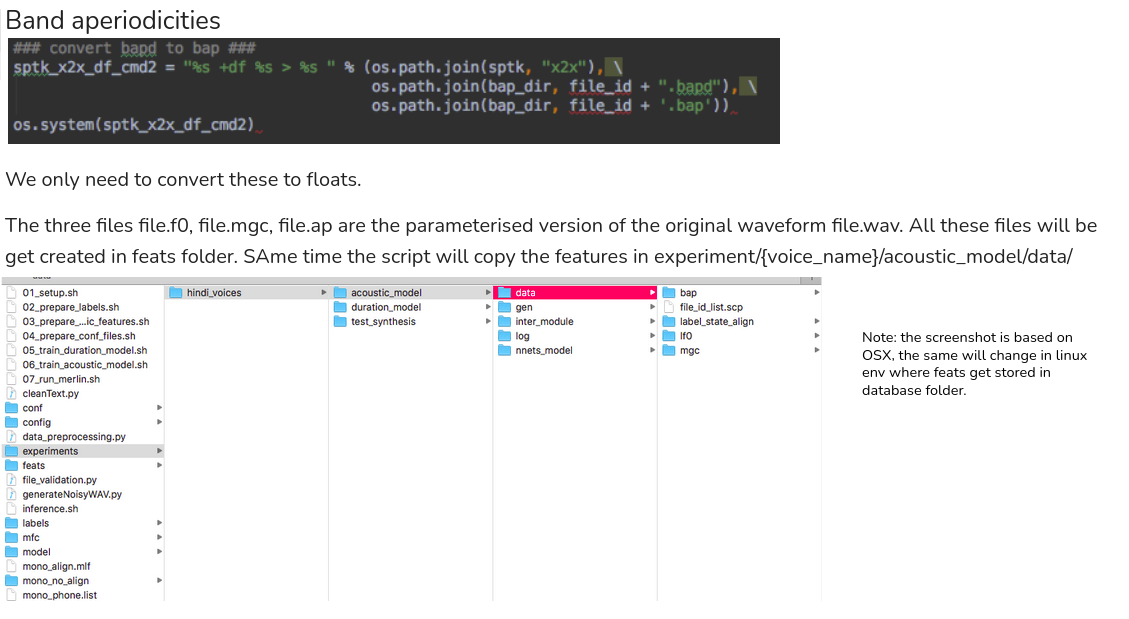

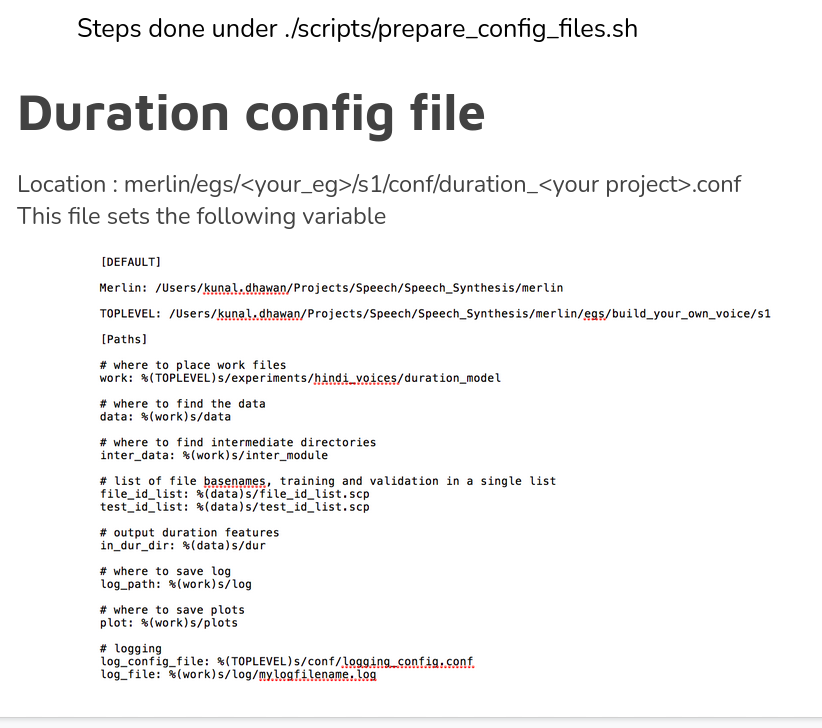
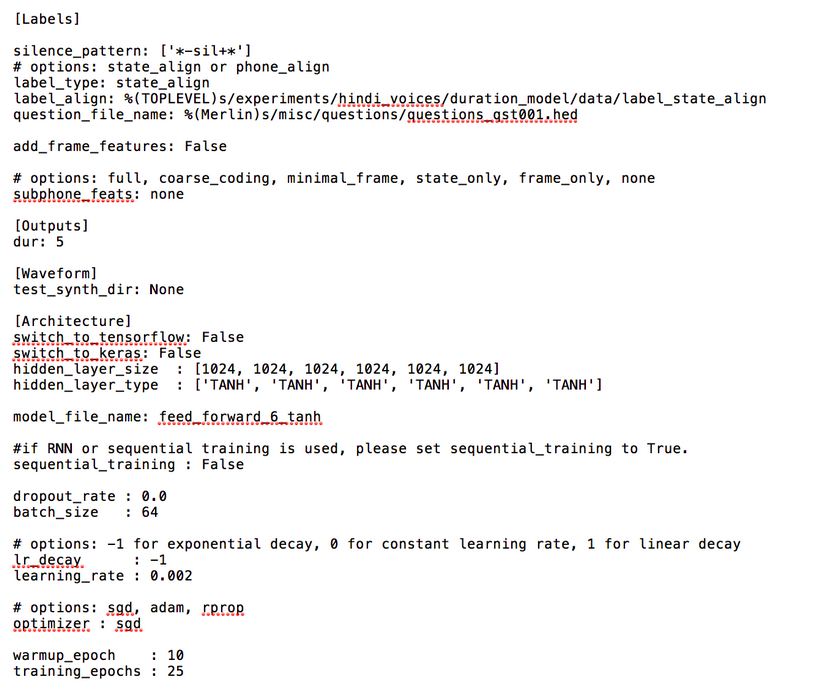
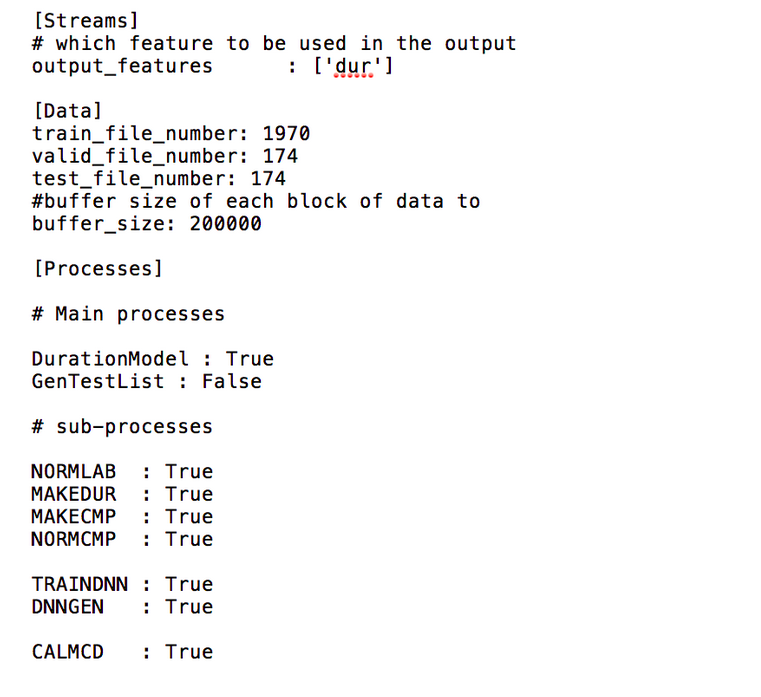
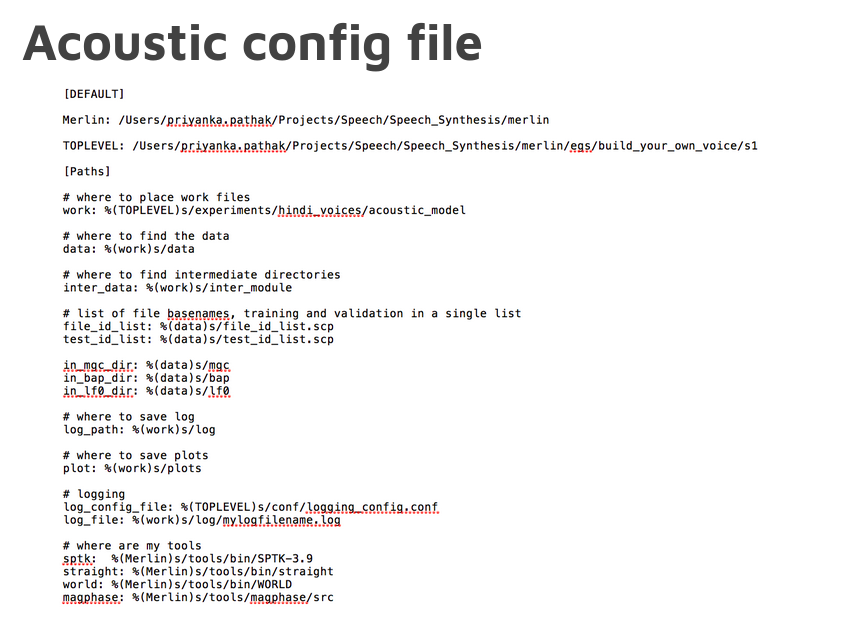
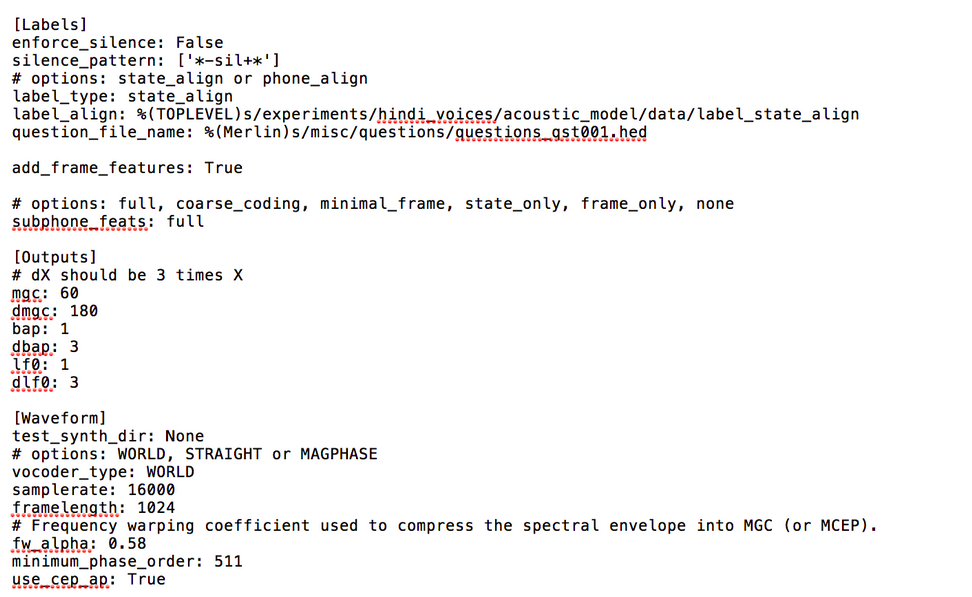
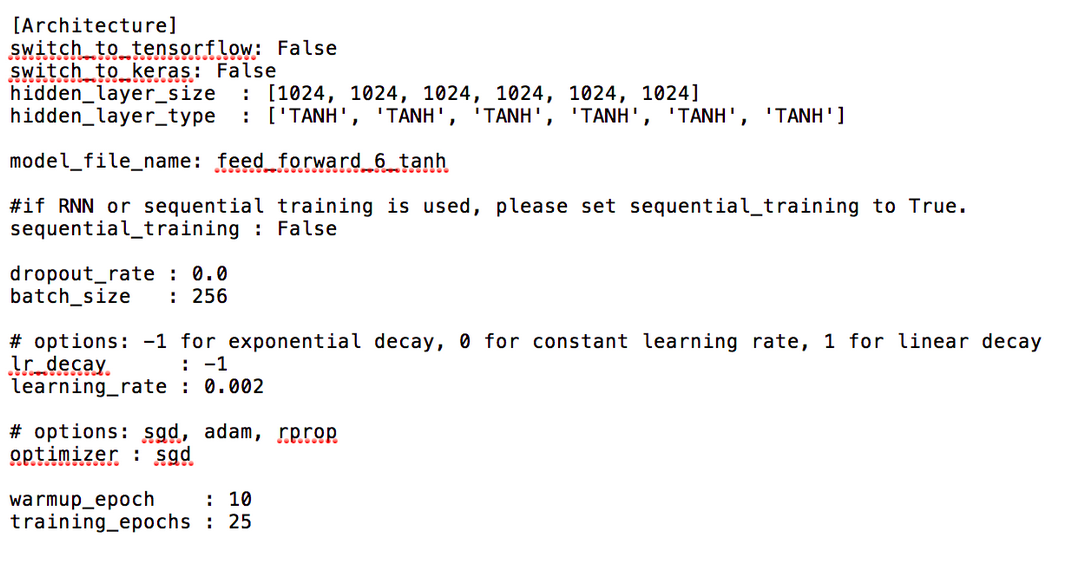
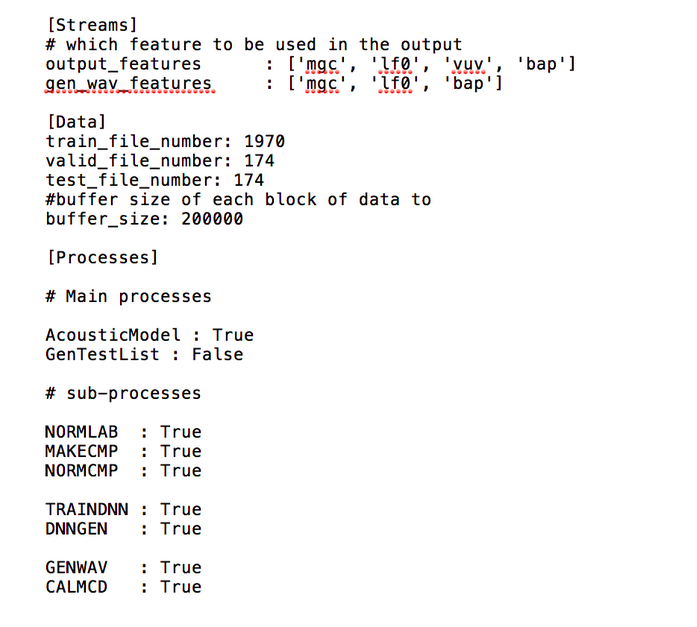
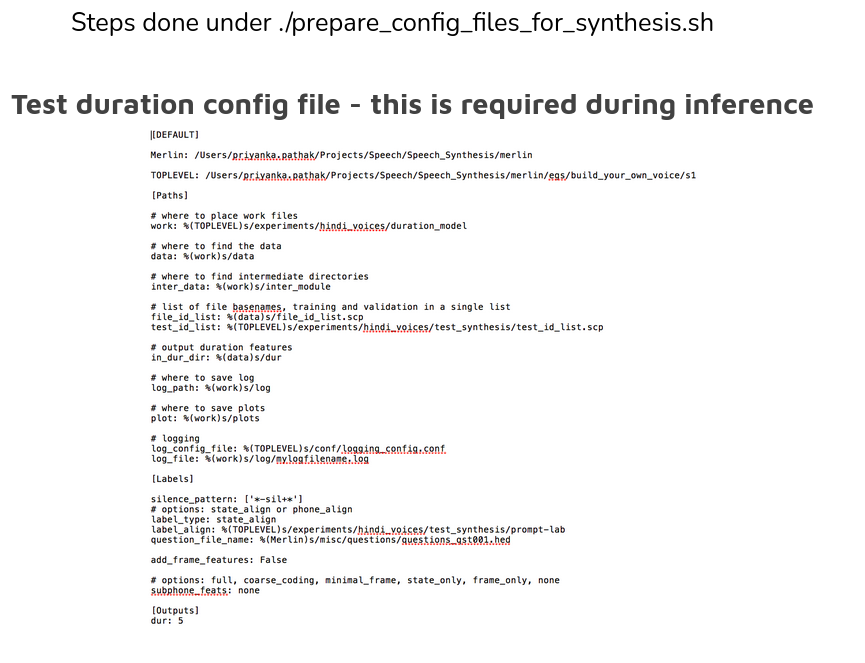
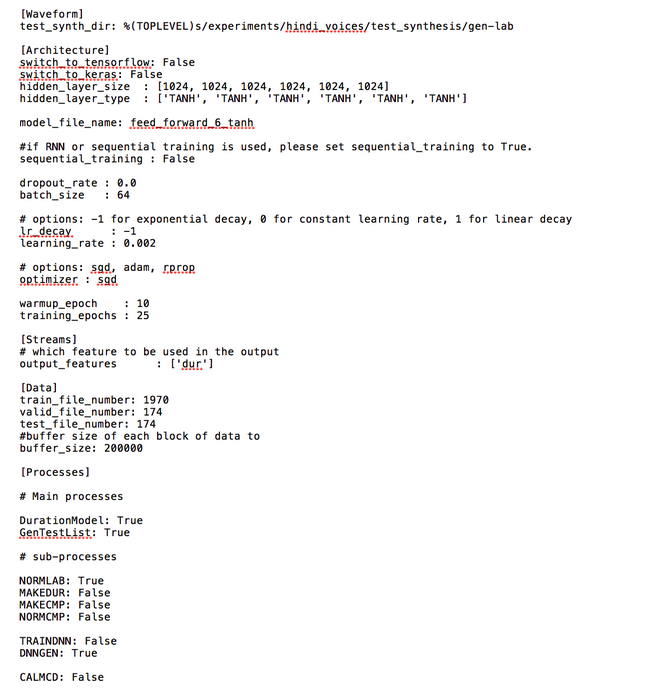
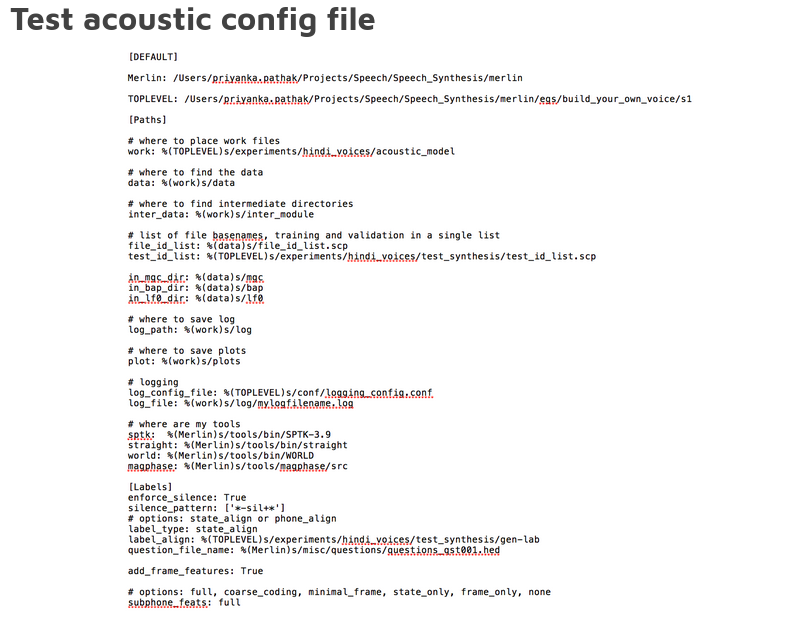
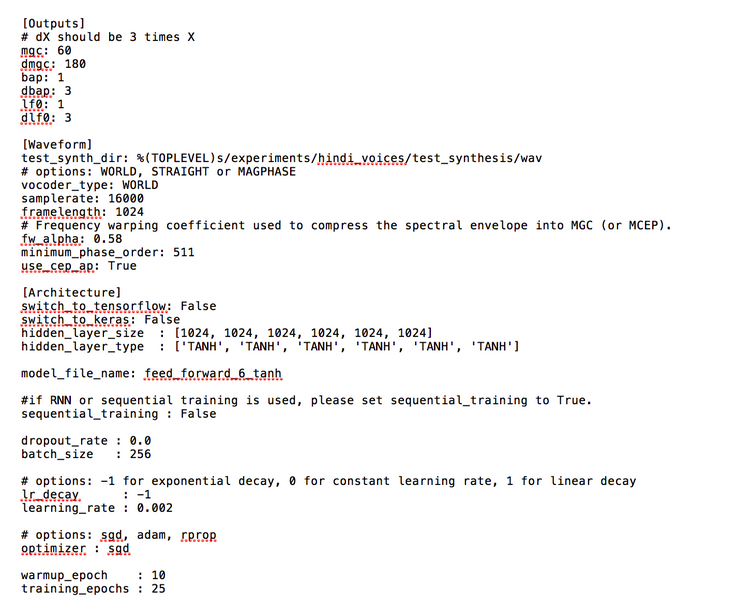
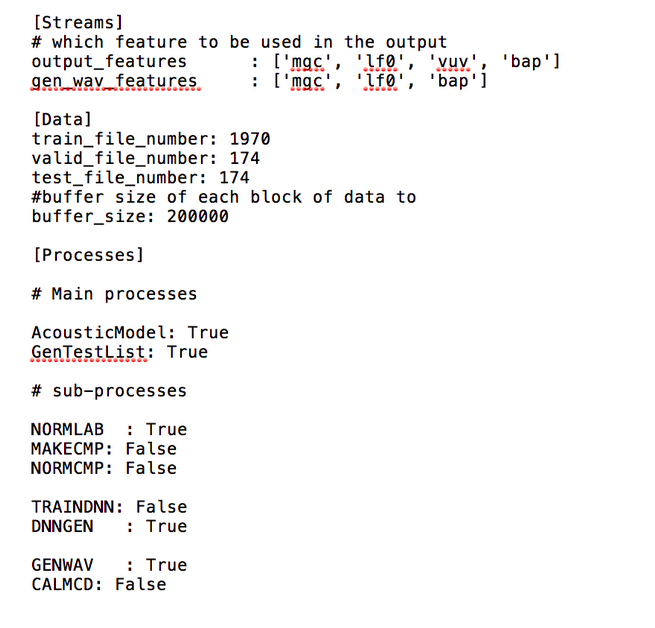



The main code is run_Merlin.py with the acoustic config file as input
We have a list of output features:
https://docs.google.com/document/d/19tEa_2KyAdW1zptVKNRuMFDySWh0fSaefaQR4TLK5g0/edit?usp=sharing
Each feature has it’s own output directory
Only HTS-style labels are supported as input to Merlin (we input the question file too while doing HTSLabelNormalisation)
We have a list of output features:
https://docs.google.com/document/d/19tEa_2KyAdW1zptVKNRuMFDySWh0fSaefaQR4TLK5g0/edit?usp=sharing
Each feature has it’s own output directory
Only HTS-style labels are supported as input to Merlin (we input the question file too while doing HTSLabelNormalisation)
