What is Language Modeling?
A Language model (LM) helps a speech recognizer to figure out how likely a word sequence is, independent of the acoustics
It helps to reduce the search space in decoding stage.
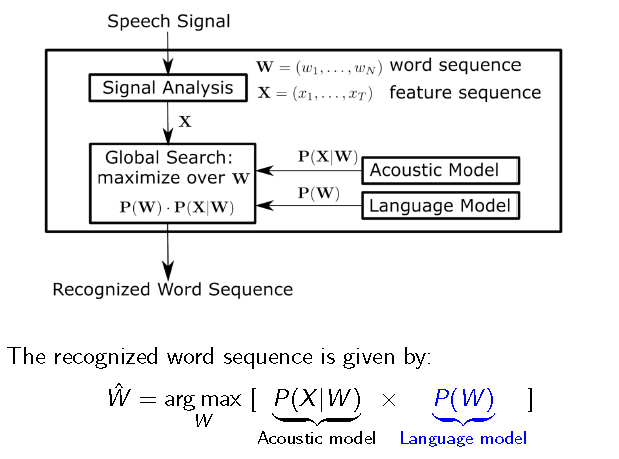
An ASR pipeline consists of an Acoustic model(what was spoken) and a Language model(what sequence of words make sense); final decoding is done by combining the information from both the models
A Language model (LM) helps a speech recognizer to figure out how likely a word sequence is, independent of the acoustics
It helps to reduce the search space in decoding stage.
An ASR pipeline consists of an Acoustic model(what was spoken) and a Language model(what sequence of words make sense); final decoding is done by combining the information from both the models
A Language Model provides the context information to distinguish between phrases that sound similar, for example:
Types of Language Models Used in practice:
1)N-gram LM
Given previous (n -1) words, it predicts the next word
Probability of observing the word sequence w1......;wn is given by
- The good can decay many ways
- The good candy came anyways
Types of Language Models Used in practice:
1)N-gram LM
Given previous (n -1) words, it predicts the next word
Probability of observing the word sequence w1......;wn is given by
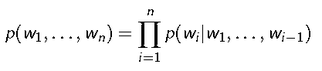
Now, modeling the sequences of all possible lengths in the language requires huge data as well as memory
Thus, to address this issue, in a N-gram LM, the conditional dependency is limited to last N words only.
Therefore, conditional probability is computed in N-gram model as follows:
Thus, to address this issue, in a N-gram LM, the conditional dependency is limited to last N words only.
Therefore, conditional probability is computed in N-gram model as follows:
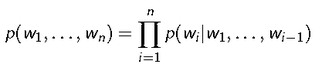
Example for N-gram sentence probabilities for different values of N is as follows:
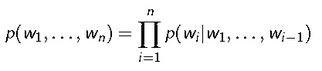
Problems with N-gram modeling:
The above problems are solved using a RNNLM- Recurrent Neural Network Language Model
2)RNNLM
It captures the semantics along with the syntactics by expressing the joint probability of word sequence in terms of FVs
Due to their structure, RNNs help temporal information to persist in future time frames
- N-gram can only model the syntactics (sequence) but not the semantics (context) of the sentence
- They cannot model long term dependencies
The above problems are solved using a RNNLM- Recurrent Neural Network Language Model
2)RNNLM
It captures the semantics along with the syntactics by expressing the joint probability of word sequence in terms of FVs
Due to their structure, RNNs help temporal information to persist in future time frames
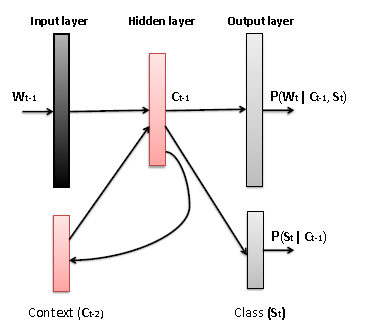
Thus now , the probability of occurrence of a word wt given context c_t-1 is given by:
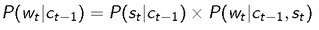
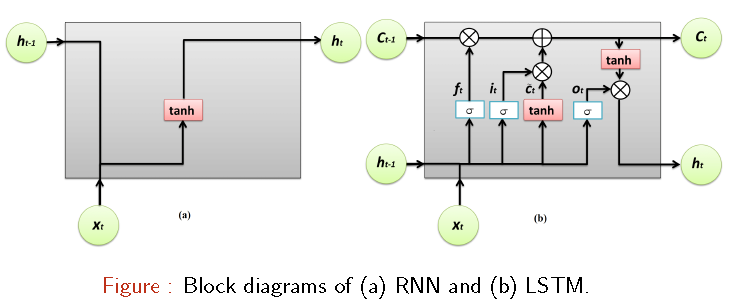
But , RNNs face the problem of vanishing gradients when very deep networks are created using them [ie words encountered in the begining of the sentence tend to have negligible effect on the occurrence of words further down in the sentence]. To solve this issue , LSTMs (Long Short Term Memory Cells) have been proposed. LSTM has memory cells which store the temporal state along with three special gates to control the information flow.
My aim in this project is to use RNN/LSTM based language models for Code-switching task. But, what is code switching?
Code Switching
In multilingual communities, the speakers often switch between two or more languages or language varieties during the conversation. In linguistics, this phenomenon is referred to as code-switching. India has more than 22 distinct native languages which are prominently used in different parts of the country. The Hindi forms the native language of half of 1.32 billion population of India. While a large portion of the remaining half, especially those residing in the metropolitan cities understands the Hindi language well enough. Besides that, being lingua-franca of India, the English language is used by around 125 million people predominantly in administration, education, law, etc. Hence, the people in India tend to switch between Hindi and English languages within the same utterance while talking to their peers, who also have the knowledge of both these languages. This makes Hindi-English code-switching extremely widespread in India.
Code Switching
In multilingual communities, the speakers often switch between two or more languages or language varieties during the conversation. In linguistics, this phenomenon is referred to as code-switching. India has more than 22 distinct native languages which are prominently used in different parts of the country. The Hindi forms the native language of half of 1.32 billion population of India. While a large portion of the remaining half, especially those residing in the metropolitan cities understands the Hindi language well enough. Besides that, being lingua-franca of India, the English language is used by around 125 million people predominantly in administration, education, law, etc. Hence, the people in India tend to switch between Hindi and English languages within the same utterance while talking to their peers, who also have the knowledge of both these languages. This makes Hindi-English code-switching extremely widespread in India.

Code switching can be of two type: intra-sentential (when mixing occurs within the sentence) and inter-sentential (mixing occurs at sentence boundaries)

Type 1 and Type 2 classification is made based on whether the embedded word sequence carries high and low contextual information, respectively
The issue of code-switching has become a common feature in several multilingual communities. Hence, there is a rising demand for an automatic speech recognition (ASR) systems that can handle the code-switched speech data. The code-switching cannot be characterized as the random mixing of words or phrases from two or more languages. In fact, the switching between the languages appears to follow some broad syntactic rules. It is hypothesized that incorporating the syntactical information in words/phrases being code-switched, would help LMs in handling the code-switched data. Motivated by that, I have not only explored the POS and the LID features but also introduced a novel code-switching location (CSL) feature in training the FLM.
But, let me first explain what a Factored Language model is:
Factored Language Model
Factored language modeling techniques are used to incorporate morphological information while training the LM . In this technique, each word wt in the vocabulary V is represented as a group of L factors denoted as:
The issue of code-switching has become a common feature in several multilingual communities. Hence, there is a rising demand for an automatic speech recognition (ASR) systems that can handle the code-switched speech data. The code-switching cannot be characterized as the random mixing of words or phrases from two or more languages. In fact, the switching between the languages appears to follow some broad syntactic rules. It is hypothesized that incorporating the syntactical information in words/phrases being code-switched, would help LMs in handling the code-switched data. Motivated by that, I have not only explored the POS and the LID features but also introduced a novel code-switching location (CSL) feature in training the FLM.
But, let me first explain what a Factored Language model is:
Factored Language Model
Factored language modeling techniques are used to incorporate morphological information while training the LM . In this technique, each word wt in the vocabulary V is represented as a group of L factors denoted as:
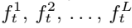
The factors can be either morphological features like roots, stems, etc., or can be any other linguistic features of that respective word. The probabilistic representation of the FLM over a sentence of T words, each with L factors, is given as;
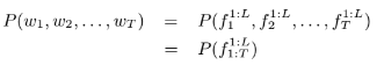
In this work, I have employed the factored N-gram LM, an extension to the traditional N-gram LM for incorporating the textual features in training the LM. It uses the same Markov independence assumption. Given the history of (n − 1) words in the sentence, the likelihood of the next word wt, can similarly be written as
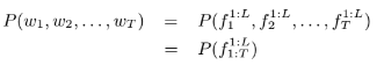
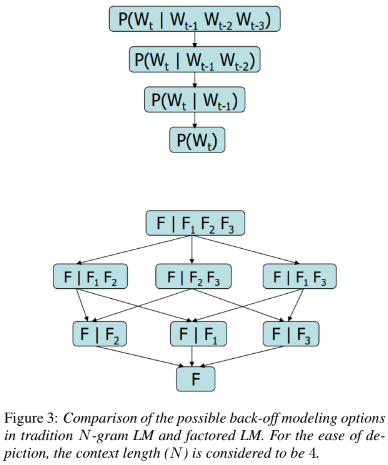
In general, the back-off techniques are employed when the LM encounters an unseen word sequence during testing. In Figure 3, the possible back-off paths for the traditional 4-gram LM and the factored 4-gram LM are shown. Modeling of the FLM involves two steps: (i) defining an appropriate set of features and, (ii) finding the FLM with the best back-off model over these features. These steps are discussed in detail in the
following subsections.
following subsections.
Features for Training the FLM:
1)Parts-of-Speech Feature(POS)
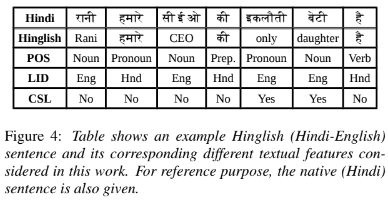
The POS feature refers to the information about the words derived based on their context and definition in the LM training text data. It mainly depends on the adjacent words in a given sentence. The POS tagging is not just tagging a list of words with their respective parts-of-speech information because based on the context, the same word might have more than one POS at different locations. When these POS is used as the feature along with the word while training the LM, it is expected to model the contextual information in a more effective way for the code-switched data. In this work , I hypothesize that in majority of the code-switching cases only the native language words are re-placed by the foreign language words; whereas the context and the parts-of-speech of that replaced foreign language word will be mostly same as that of the native language word. This fact can be visualized from a pair of Hindi and Hindi-English sentences given in Figure 4. Hence, for extracting the POS feature for Hindi-English code-switching sentences, a Hindi POS tagger has been employed.
1)Parts-of-Speech Feature(POS)
The POS feature refers to the information about the words derived based on their context and definition in the LM training text data. It mainly depends on the adjacent words in a given sentence. The POS tagging is not just tagging a list of words with their respective parts-of-speech information because based on the context, the same word might have more than one POS at different locations. When these POS is used as the feature along with the word while training the LM, it is expected to model the contextual information in a more effective way for the code-switched data. In this work , I hypothesize that in majority of the code-switching cases only the native language words are re-placed by the foreign language words; whereas the context and the parts-of-speech of that replaced foreign language word will be mostly same as that of the native language word. This fact can be visualized from a pair of Hindi and Hindi-English sentences given in Figure 4. Hence, for extracting the POS feature for Hindi-English code-switching sentences, a Hindi POS tagger has been employed.
2)Language Identification Factor
The information about the language of words in the code-switching sentences is shown to impact the predictability of word-sequences in the data. This feature has been referred to as language identification (LID) feature. In this work, a word in the given code-switched sentence is tagged as ‘Eng’ if it is present in the English word list and ‘Hnd’ if it is present in the Hindi word list, otherwise tagged as ‘unk’, i.e., an unknown word. The LID feature for an example sentence is also shown in above figure.
3)Code-Switching Location Factor
During code-switching, the foreign language words are inserted into the native language sentences mostly without altering the semantics and syntactics of the native language. Thus, like the POS factor, code-switching is also expected to adhere certain semantic and syntactic rules. To capture this information, we have used a novel textual feature that identifies the locations where the code-switching can potentially occur or not. This feature is referred to as the code-switching location (CSL) feature in this documentation. To introduce the CSL feature in the FLM training data, I have created two word lists, one is called ‘non-code-switching list’ covering Hindi words + English words like proper nouns and abbreviations (which would not ever undergo code switching) , while the other is called ‘code-switching list’ covering English words in the Hindi-English code-switching training data. Later, by employing the word level search, each word in the training sentences has been tagged as ‘Yes’ if it belongs to ‘code-switching list’ and ‘No’ if it belongs to ‘non-code-switching list’, otherwise tagged as ‘unk’. Note that, there are few English words like proper nouns and abbreviations which remain unaltered while code-switching. So, those English words are added to the ‘non-
code-switching list’. On account of that, the CSL feature is not only different from the LID feature but also the former turns out
to be more effective than the later. The CSL feature has also been shown in the above example.
Experimentation and Result
Database
To evaluate the above proposed method and due to unavailability of public Hinglish databases, I have crawled Hindi-English code switched data from a few web blogs(https://shoutmehindi.com ; https://notesinhinglish.blogspot.in ; https://www.techyukti.com ; http://www.learncpp.com) having different context. I was able to obtain around 15000 sentences using the above method which had around 8000 unique English words and 6000 unique Hindi words (the sentences were divided into the train , test and dev set in the ratio of 12:2:1). It can be noted that there are more unique English words than unique Hindi words. This is attributed to the fact that, the code-switching happen when the speaker either wants to emphasize certain words or runs out of Hindi vocabulary. As a result, for a limited context, the involved English vocabulary happens to be much higher than Hindi vocabulary.
Parameter Tuning
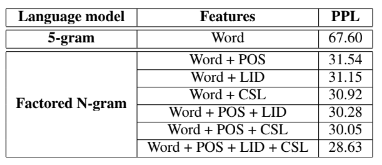
The normal and the factored N-gram language models used in the experimentation are trained using the SRILM toolkit. For optimizing the structure of FLMs, a genetic algorithm (GA) based FLM (GA-FLM) has been trained using the GAFLM toolkit from Washington university.It was observed that context length of 5 led to the best perplexity on the dev set.The result ( in terms of perplexity ) for all the factors discussed above are:
The information about the language of words in the code-switching sentences is shown to impact the predictability of word-sequences in the data. This feature has been referred to as language identification (LID) feature. In this work, a word in the given code-switched sentence is tagged as ‘Eng’ if it is present in the English word list and ‘Hnd’ if it is present in the Hindi word list, otherwise tagged as ‘unk’, i.e., an unknown word. The LID feature for an example sentence is also shown in above figure.
3)Code-Switching Location Factor
During code-switching, the foreign language words are inserted into the native language sentences mostly without altering the semantics and syntactics of the native language. Thus, like the POS factor, code-switching is also expected to adhere certain semantic and syntactic rules. To capture this information, we have used a novel textual feature that identifies the locations where the code-switching can potentially occur or not. This feature is referred to as the code-switching location (CSL) feature in this documentation. To introduce the CSL feature in the FLM training data, I have created two word lists, one is called ‘non-code-switching list’ covering Hindi words + English words like proper nouns and abbreviations (which would not ever undergo code switching) , while the other is called ‘code-switching list’ covering English words in the Hindi-English code-switching training data. Later, by employing the word level search, each word in the training sentences has been tagged as ‘Yes’ if it belongs to ‘code-switching list’ and ‘No’ if it belongs to ‘non-code-switching list’, otherwise tagged as ‘unk’. Note that, there are few English words like proper nouns and abbreviations which remain unaltered while code-switching. So, those English words are added to the ‘non-
code-switching list’. On account of that, the CSL feature is not only different from the LID feature but also the former turns out
to be more effective than the later. The CSL feature has also been shown in the above example.
Experimentation and Result
Database
To evaluate the above proposed method and due to unavailability of public Hinglish databases, I have crawled Hindi-English code switched data from a few web blogs(https://shoutmehindi.com ; https://notesinhinglish.blogspot.in ; https://www.techyukti.com ; http://www.learncpp.com) having different context. I was able to obtain around 15000 sentences using the above method which had around 8000 unique English words and 6000 unique Hindi words (the sentences were divided into the train , test and dev set in the ratio of 12:2:1). It can be noted that there are more unique English words than unique Hindi words. This is attributed to the fact that, the code-switching happen when the speaker either wants to emphasize certain words or runs out of Hindi vocabulary. As a result, for a limited context, the involved English vocabulary happens to be much higher than Hindi vocabulary.
Parameter Tuning
The normal and the factored N-gram language models used in the experimentation are trained using the SRILM toolkit. For optimizing the structure of FLMs, a genetic algorithm (GA) based FLM (GA-FLM) has been trained using the GAFLM toolkit from Washington university.It was observed that context length of 5 led to the best perplexity on the dev set.The result ( in terms of perplexity ) for all the factors discussed above are:
Discussion
We observe that when the factored N-gram LM is trained using the POS inormation as a feature, a significant reduction in PPL is achieved compared to that of the traditional N-gram LMs. This is because the POS feature is not only tagging a list of words with their respective parts-of-speech but also is based on the context. Even when a native word is replaced by a foreign word, the POS feature will mostly remain unchanged. Therefore, by employing the POS feature along with the word while training the LM, the context information will help to predict the Hindi-
English code-switched sentences. Also, we note a significant improvement in the recognition performance when the LID feature alone is used in training the factored N-gram LM. This shows that even the language switching happens by following some systematic rules. Not all words in the native sentence can be switched. Thus, LID feature provides some extra information about the next word in the sequence to be predicted. From above table we note that the proposed CSL feature resulted in significant improvement similar to that obtained with the LID feature.
This indicates that, like the POS and the LID features, the CSL feature also adhere certain semantic and syntactic rules. Later, when the factored N-gram LMs is trained by combining CSL feature along with the POS and LID features, further reduction in PPL is achieved. This result shows that the information captured by the CSL feature is additive to that of the POS and LID features.
We observe that when the factored N-gram LM is trained using the POS inormation as a feature, a significant reduction in PPL is achieved compared to that of the traditional N-gram LMs. This is because the POS feature is not only tagging a list of words with their respective parts-of-speech but also is based on the context. Even when a native word is replaced by a foreign word, the POS feature will mostly remain unchanged. Therefore, by employing the POS feature along with the word while training the LM, the context information will help to predict the Hindi-
English code-switched sentences. Also, we note a significant improvement in the recognition performance when the LID feature alone is used in training the factored N-gram LM. This shows that even the language switching happens by following some systematic rules. Not all words in the native sentence can be switched. Thus, LID feature provides some extra information about the next word in the sequence to be predicted. From above table we note that the proposed CSL feature resulted in significant improvement similar to that obtained with the LID feature.
This indicates that, like the POS and the LID features, the CSL feature also adhere certain semantic and syntactic rules. Later, when the factored N-gram LMs is trained by combining CSL feature along with the POS and LID features, further reduction in PPL is achieved. This result shows that the information captured by the CSL feature is additive to that of the POS and LID features.
The above work has been accepted as a journal paper in Computer Speech & Language and can be accessed at https://www.sciencedirect.com/science/article/abs/pii/S0885230820300322
